kwarray package¶
Submodules¶
- kwarray.algo_assignment module
- kwarray.algo_setcover module
- kwarray.arrayapi module
_ImplRegistry_torchmethod()_numpymethod()_apimethod()TorchImplsTorchImpls.is_tensorTorchImpls.is_numpyTorchImpls.result_type()TorchImpls.cat()TorchImpls.hstack()TorchImpls.vstack()TorchImpls.atleast_nd()TorchImpls.view()TorchImpls.take()TorchImpls.compress()TorchImpls.tile()TorchImpls.repeat()TorchImpls.T()TorchImpls.transpose()TorchImpls.numel()TorchImpls.full_like()TorchImpls.empty_like()TorchImpls.zeros_like()TorchImpls.ones_like()TorchImpls.full()TorchImpls.empty()TorchImpls.zeros()TorchImpls.ones()TorchImpls.argmax()TorchImpls.argmin()TorchImpls.argsort()TorchImpls.max()TorchImpls.min()TorchImpls.max_argmax()TorchImpls.min_argmin()TorchImpls.maximum()TorchImpls.minimum()TorchImpls.array_equal()TorchImpls.matmul()TorchImpls.sum()TorchImpls.nan_to_num()TorchImpls.copy()TorchImpls.log()TorchImpls.log2()TorchImpls.any()TorchImpls.all()TorchImpls.nonzero()TorchImpls.astype()TorchImpls.tensor()TorchImpls.numpy()TorchImpls.tolist()TorchImpls.contiguous()TorchImpls.pad()TorchImpls.asarray()TorchImpls.ensure()TorchImpls.dtype_kind()TorchImpls.floor()TorchImpls.ceil()TorchImpls.ifloor()TorchImpls.iceil()TorchImpls.round()TorchImpls.iround()TorchImpls.clip()TorchImpls.softmax()
NumpyImplsNumpyImpls.is_tensorNumpyImpls.is_numpyNumpyImpls.hstack()NumpyImpls.vstack()NumpyImpls.result_type()NumpyImpls.cat()NumpyImpls.atleast_nd()NumpyImpls.view()NumpyImpls.take()NumpyImpls.compress()NumpyImpls.repeat()NumpyImpls.tile()NumpyImpls.T()NumpyImpls.transpose()NumpyImpls.numel()NumpyImpls.empty_like()NumpyImpls.full_like()NumpyImpls.zeros_like()NumpyImpls.ones_like()NumpyImpls.full()NumpyImpls.empty()NumpyImpls.zeros()NumpyImpls.ones()NumpyImpls.argmax()NumpyImpls.argmin()NumpyImpls.argsort()NumpyImpls.max()NumpyImpls.min()NumpyImpls.max_argmax()NumpyImpls.min_argmin()NumpyImpls.sum()NumpyImpls.maximum()NumpyImpls.minimum()NumpyImpls.matmulNumpyImpls.nan_to_num()NumpyImpls.array_equal()NumpyImpls.logNumpyImpls.log2NumpyImpls.any()NumpyImpls.all()NumpyImpls.copy()NumpyImpls.nonzero()NumpyImpls.astype()NumpyImpls.tensor()NumpyImpls.numpy()NumpyImpls.tolist()NumpyImpls.contiguous()NumpyImpls.pad()NumpyImpls.asarray()NumpyImpls.ensure()NumpyImpls.dtype_kind()NumpyImpls.floor()NumpyImpls.ceil()NumpyImpls.ifloor()NumpyImpls.iceil()NumpyImpls.round()NumpyImpls.iround()NumpyImpls.clip()NumpyImpls.softmax()NumpyImpls.kron()
ArrayAPIArrayAPI._torchArrayAPI._numpyArrayAPI.impl()ArrayAPI.coerce()ArrayAPI.result_type()ArrayAPI.cat()ArrayAPI.hstack()ArrayAPI.vstack()ArrayAPI.take()ArrayAPI.compress()ArrayAPI.repeat()ArrayAPI.tile()ArrayAPI.view()ArrayAPI.numel()ArrayAPI.atleast_nd()ArrayAPI.full_like()ArrayAPI.ones_like()ArrayAPI.zeros_like()ArrayAPI.empty_like()ArrayAPI.sum()ArrayAPI.argsort()ArrayAPI.argmax()ArrayAPI.argmin()ArrayAPI.max()ArrayAPI.min()ArrayAPI.max_argmax()ArrayAPI.min_argmin()ArrayAPI.maximum()ArrayAPI.minimum()ArrayAPI.matmul()ArrayAPI.astype()ArrayAPI.nonzero()ArrayAPI.nan_to_num()ArrayAPI.tensor()ArrayAPI.numpy()ArrayAPI.tolist()ArrayAPI.asarray()ArrayAPI.T()ArrayAPI.transpose()ArrayAPI.contiguous()ArrayAPI.pad()ArrayAPI.dtype_kind()ArrayAPI.any()ArrayAPI.all()ArrayAPI.array_equal()ArrayAPI.log2()ArrayAPI.log()ArrayAPI.copy()ArrayAPI.iceil()ArrayAPI.ifloor()ArrayAPI.floor()ArrayAPI.ceil()ArrayAPI.round()ArrayAPI.iround()ArrayAPI.clip()ArrayAPI.softmax()
TorchNumpyCompat_torch_dtype_lut()dtype_info()
- kwarray.dataframe_light module
LocLightDataFrameLightDataFrameLight.ilocDataFrameLight.valuesDataFrameLight.locDataFrameLight.to_string()DataFrameLight.to_dict()DataFrameLight.pandas()DataFrameLight._pandas()DataFrameLight._demodata()DataFrameLight.columnsDataFrameLight.sort_values()DataFrameLight.keys()DataFrameLight._getrow()DataFrameLight._getcol()DataFrameLight._getcols()DataFrameLight.get()DataFrameLight.clear()DataFrameLight.compress()DataFrameLight.take()DataFrameLight.copy()DataFrameLight.extend()DataFrameLight.union()DataFrameLight.concat()DataFrameLight.from_pandas()DataFrameLight.from_dict()DataFrameLight.reset_index()DataFrameLight.groupby()DataFrameLight.rename()DataFrameLight.iterrows()
DataFrameArray
- kwarray.distributions module
Value_issubclass2()_isinstance2()ParameterizedParameterizedList_BinOpMixin_RBinOpMixinDistribution_coerce_timedelta()_generate_on_a_time_budget()DiscreteDistributionContinuousDistributionMixedDistributionMixtureComposed_trysample()CoerceErrorCastErrorUniformExponentialConstantDiscreteUniformNormalTruncNormalBernoulliBinomialCategoricalNonlinearUniformCategoryUniformPDFSeeded_test_distributions()_process_docstrings()
- kwarray.fast_rand module
- kwarray.util_averages module
- kwarray.util_groups module
- kwarray.util_misc module
- kwarray.util_numpy module
- kwarray.util_random module
- kwarray.util_robust module
- kwarray.util_slices module
- kwarray.util_slider module
- kwarray.util_torch module
Module contents¶
The kwarray module implements a small set of pure-python extensions to
numpy and torch along with a few select algorithms. Each module contains
module level docstring that gives a rough idea of the utilities in each module,
and each function or class itself contains a docstring with more details and
examples.
KWarray is part of Kitware’s computer vision Python suite:
- class kwarray.ArrayAPI[source]¶
Bases:
objectCompatability API between torch and numpy.
The API defines classmethods that work on both Tensors and ndarrays. As such the user can simply use
kwarray.ArrayAPI.<funcname>and it will return the expected result for both Tensor and ndarray types.However, this is inefficient because it requires us to check the type of the input for every API call. Therefore it is recommended that you use the
ArrayAPI.coerce()function, which takes as input the data you want to operate on. It performs the type check once, and then returns another object that defines with an identical API, but specific to the given data type. This means that we can ignore type checks on future calls of the specific implementation. See examples for more details.Example
>>> # Use the easy-to-use, but inefficient array api >>> # xdoctest: +REQUIRES(module:torch) >>> import kwarray >>> import torch >>> take = kwarray.ArrayAPI.take >>> np_data = np.arange(0, 143).reshape(11, 13) >>> pt_data = torch.LongTensor(np_data) >>> indices = [1, 3, 5, 7, 11, 13, 17, 21] >>> idxs0 = [1, 3, 5, 7] >>> idxs1 = [1, 3, 5, 7, 11] >>> assert np.allclose(take(np_data, indices), take(pt_data, indices)) >>> assert np.allclose(take(np_data, idxs0, 0), take(pt_data, idxs0, 0)) >>> assert np.allclose(take(np_data, idxs1, 1), take(pt_data, idxs1, 1))
Example
>>> # Use the easy-to-use, but inefficient array api >>> # xdoctest: +REQUIRES(module:torch) >>> import kwarray >>> import torch >>> compress = kwarray.ArrayAPI.compress >>> np_data = np.arange(0, 143).reshape(11, 13) >>> pt_data = torch.LongTensor(np_data) >>> flags = (np_data % 2 == 0).ravel() >>> f0 = (np_data % 2 == 0)[:, 0] >>> f1 = (np_data % 2 == 0)[0, :] >>> assert np.allclose(compress(np_data, flags), compress(pt_data, flags)) >>> assert np.allclose(compress(np_data, f0, 0), compress(pt_data, f0, 0)) >>> assert np.allclose(compress(np_data, f1, 1), compress(pt_data, f1, 1))
Example
>>> # Use ArrayAPI to coerce an identical API that doesnt do type checks >>> # xdoctest: +REQUIRES(module:torch) >>> import kwarray >>> import torch >>> np_data = np.arange(0, 15).reshape(3, 5) >>> pt_data = torch.LongTensor(np_data) >>> # The new ``impl`` object has the same API as ArrayAPI, but works >>> # specifically on torch Tensors. >>> impl = kwarray.ArrayAPI.coerce(pt_data) >>> flat_data = impl.view(pt_data, -1) >>> print('flat_data = {!r}'.format(flat_data)) flat_data = tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]) >>> # The new ``impl`` object has the same API as ArrayAPI, but works >>> # specifically on numpy ndarrays. >>> impl = kwarray.ArrayAPI.coerce(np_data) >>> flat_data = impl.view(np_data, -1) >>> print('flat_data = {!r}'.format(flat_data)) flat_data = array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
- _torch¶
alias of
TorchImpls
- _numpy¶
alias of
NumpyImpls
- static impl(data)[source]¶
Returns a namespace suitable for operating on the input data type
- Parameters:
data (ndarray | Tensor) – data to be operated on
- static result_type(*arrays_and_dtypes)[source]¶
Return type from promotion rules
Example
>>> import kwarray >>> kwarray.ArrayAPI.result_type(float, np.uint8, np.float32, np.float16) >>> # xdoctest: +REQUIRES(module:torch) >>> import torch >>> kwarray.ArrayAPI.result_type(torch.int32, torch.int64)
- static take(data, *args, **kwargs)¶
- static compress(data, *args, **kwargs)¶
- static repeat(data, *args, **kwargs)¶
- static tile(data, *args, **kwargs)¶
- static view(data, *args, **kwargs)¶
- static numel(data, *args, **kwargs)¶
- static atleast_nd(data, *args, **kwargs)¶
- static full_like(data, *args, **kwargs)¶
- static ones_like(data, *args, **kwargs)¶
- static zeros_like(data, *args, **kwargs)¶
- static empty_like(data, *args, **kwargs)¶
- static sum(data, *args, **kwargs)¶
- static argsort(data, *args, **kwargs)¶
- static argmax(data, *args, **kwargs)¶
- static argmin(data, *args, **kwargs)¶
- static max(data, *args, **kwargs)¶
- static min(data, *args, **kwargs)¶
- static max_argmax(data, *args, **kwargs)¶
- static min_argmin(data, *args, **kwargs)¶
- static maximum(data, *args, **kwargs)¶
- static minimum(data, *args, **kwargs)¶
- static matmul(data, *args, **kwargs)¶
- static astype(data, *args, **kwargs)¶
- static nonzero(data, *args, **kwargs)¶
- static nan_to_num(data, *args, **kwargs)¶
- static tensor(data, *args, **kwargs)¶
- static numpy(data, *args, **kwargs)¶
- static tolist(data, *args, **kwargs)¶
- static asarray(data, *args, **kwargs)¶
- static T(data, *args, **kwargs)¶
- static transpose(data, *args, **kwargs)¶
- static contiguous(data, *args, **kwargs)¶
- static pad(data, *args, **kwargs)¶
- static dtype_kind(data, *args, **kwargs)¶
- static any(data, *args, **kwargs)¶
- static all(data, *args, **kwargs)¶
- static array_equal(data, *args, **kwargs)¶
- static log2(data, *args, **kwargs)¶
- static log(data, *args, **kwargs)¶
- static copy(data, *args, **kwargs)¶
- static iceil(data, *args, **kwargs)¶
- static ifloor(data, *args, **kwargs)¶
- static floor(data, *args, **kwargs)¶
- static ceil(data, *args, **kwargs)¶
- static round(data, *args, **kwargs)¶
- static iround(data, *args, **kwargs)¶
- static clip(data, *args, **kwargs)¶
- static softmax(data, *args, **kwargs)¶
- class kwarray.DataFrameArray(data=None, columns=None)[source]¶
Bases:
DataFrameLightDataFrameLight assumes the backend is a Dict[list] DataFrameArray assumes the backend is a Dict[ndarray]
Take and compress are much faster, but extend and union are slower
- class kwarray.DataFrameLight(data=None, columns=None)[source]¶
Bases:
NiceReprImplements a subset of the pandas.DataFrame API
The API is restricted to facilitate speed tradeoffs
Note
Assumes underlying data is Dict[list|ndarray]. If the data is known to be a Dict[ndarray] use DataFrameArray instead, which has faster implementations for some operations.
Note
pandas.DataFrame is slow. DataFrameLight is faster. It is a tad more restrictive though.
Example
>>> self = DataFrameLight({}) >>> print('self = {!r}'.format(self)) >>> self = DataFrameLight({'a': [0, 1, 2], 'b': [2, 3, 4]}) >>> print('self = {!r}'.format(self)) >>> item = self.iloc[0] >>> print('item = {!r}'.format(item))
Benchmark
>>> # BENCHMARK >>> # xdoc: +REQUIRES(--bench) >>> from kwarray.dataframe_light import * # NOQA >>> import ubelt as ub >>> NUM = 1000 >>> print('NUM = {!r}'.format(NUM)) >>> # to_dict conversions >>> print('==============') >>> print('====== to_dict conversions =====') >>> _keys = ['list', 'dict', 'series', 'split', 'records', 'index'] >>> results = [] >>> df = DataFrameLight._demodata(num=NUM).pandas() >>> ti = ub.Timerit(verbose=False, unit='ms') >>> for key in _keys: >>> result = ti.reset(key).call(lambda: df.to_dict(orient=key)) >>> results.append((result.mean(), result.report())) >>> key = 'series+numpy' >>> result = ti.reset(key).call(lambda: {k: v.values for k, v in df.to_dict(orient='series').items()}) >>> results.append((result.mean(), result.report())) >>> print('\n'.join([t[1] for t in sorted(results)])) >>> print('==============') >>> print('====== DFLight Conversions =======') >>> ti = ub.Timerit(verbose=True, unit='ms') >>> key = 'self.pandas' >>> self = DataFrameLight(df) >>> ti.reset(key).call(lambda: self.pandas()) >>> key = 'light-from-pandas' >>> ti.reset(key).call(lambda: DataFrameLight(df)) >>> key = 'light-from-dict' >>> ti.reset(key).call(lambda: DataFrameLight(self._data)) >>> print('==============') >>> print('====== BENCHMARK: .LOC[] =======') >>> ti = ub.Timerit(num=20, bestof=4, verbose=True, unit='ms') >>> df_light = DataFrameLight._demodata(num=NUM) >>> # xdoctest: +REQUIRES(module:pandas) >>> df_heavy = df_light.pandas() >>> series_data = df_heavy.to_dict(orient='series') >>> list_data = df_heavy.to_dict(orient='list') >>> np_data = {k: v.values for k, v in df_heavy.to_dict(orient='series').items()} >>> for timer in ti.reset('DF-heavy.iloc'): >>> with timer: >>> for i in range(NUM): >>> df_heavy.iloc[i] >>> for timer in ti.reset('DF-heavy.loc'): >>> with timer: >>> for i in range(NUM): >>> df_heavy.iloc[i] >>> for timer in ti.reset('dict[SERIES].loc'): >>> with timer: >>> for i in range(NUM): >>> {key: series_data[key].loc[i] for key in series_data.keys()} >>> for timer in ti.reset('dict[SERIES].iloc'): >>> with timer: >>> for i in range(NUM): >>> {key: series_data[key].iloc[i] for key in series_data.keys()} >>> for timer in ti.reset('dict[SERIES][]'): >>> with timer: >>> for i in range(NUM): >>> {key: series_data[key][i] for key in series_data.keys()} >>> for timer in ti.reset('dict[NDARRAY][]'): >>> with timer: >>> for i in range(NUM): >>> {key: np_data[key][i] for key in np_data.keys()} >>> for timer in ti.reset('dict[list][]'): >>> with timer: >>> for i in range(NUM): >>> {key: list_data[key][i] for key in np_data.keys()} >>> for timer in ti.reset('DF-Light.iloc/loc'): >>> with timer: >>> for i in range(NUM): >>> df_light.iloc[i] >>> for timer in ti.reset('DF-Light._getrow'): >>> with timer: >>> for i in range(NUM): >>> df_light._getrow(i) NUM = 1000 ============== ====== to_dict conversions ===== Timed best=0.022 ms, mean=0.022 ± 0.0 ms for series Timed best=0.059 ms, mean=0.059 ± 0.0 ms for series+numpy Timed best=0.315 ms, mean=0.315 ± 0.0 ms for list Timed best=0.895 ms, mean=0.895 ± 0.0 ms for dict Timed best=2.705 ms, mean=2.705 ± 0.0 ms for split Timed best=5.474 ms, mean=5.474 ± 0.0 ms for records Timed best=7.320 ms, mean=7.320 ± 0.0 ms for index ============== ====== DFLight Conversions ======= Timed best=1.798 ms, mean=1.798 ± 0.0 ms for self.pandas Timed best=0.064 ms, mean=0.064 ± 0.0 ms for light-from-pandas Timed best=0.010 ms, mean=0.010 ± 0.0 ms for light-from-dict ============== ====== BENCHMARK: .LOC[] ======= Timed best=101.365 ms, mean=101.564 ± 0.2 ms for DF-heavy.iloc Timed best=102.038 ms, mean=102.273 ± 0.2 ms for DF-heavy.loc Timed best=29.357 ms, mean=29.449 ± 0.1 ms for dict[SERIES].loc Timed best=21.701 ms, mean=22.014 ± 0.3 ms for dict[SERIES].iloc Timed best=11.469 ms, mean=11.566 ± 0.1 ms for dict[SERIES][] Timed best=0.807 ms, mean=0.826 ± 0.0 ms for dict[NDARRAY][] Timed best=0.478 ms, mean=0.492 ± 0.0 ms for dict[list][] Timed best=0.969 ms, mean=0.994 ± 0.0 ms for DF-Light.iloc/loc Timed best=0.760 ms, mean=0.776 ± 0.0 ms for DF-Light._getrow
- property iloc¶
- property values¶
- property loc¶
- to_dict(orient='dict', into=<class 'dict'>)[source]¶
Convert the data frame into a dictionary.
- Parameters:
orient (str) – Currently naitively suports orient in {‘dict’, ‘list’}, otherwise we fallback to pandas conversion and call its to_dict method.
into (type) – type of dictionary to transform into
- Returns:
dict
Example
>>> from kwarray.dataframe_light import * # NOQA >>> self = DataFrameLight._demodata(num=7) >>> print(self.to_dict(orient='dict')) >>> print(self.to_dict(orient='list'))
- pandas()[source]¶
Convert back to pandas if you need the full API
- Return type:
pd.DataFrame
Example
>>> # xdoctest: +REQUIRES(module:pandas) >>> df_light = DataFrameLight._demodata(num=7) >>> df_heavy = df_light.pandas() >>> got = DataFrameLight(df_heavy) >>> assert got._data == df_light._data
- classmethod _demodata(num=7)[source]¶
Example
>>> self = DataFrameLight._demodata(num=7) >>> print('self = {!r}'.format(self)) >>> other = DataFrameLight._demodata(num=11) >>> print('other = {!r}'.format(other)) >>> both = self.union(other) >>> print('both = {!r}'.format(both)) >>> assert both is not self >>> assert other is not self
- property columns¶
- take(indices, inplace=False)[source]¶
Return the elements in the given positional indices along an axis.
- Parameters:
inplace (bool) – NOT PART OF PANDAS API
Note
assumes axis=0
Example
>>> df_light = DataFrameLight._demodata(num=7) >>> indices = [0, 2, 3] >>> sub1 = df_light.take(indices) >>> # xdoctest: +REQUIRES(module:pandas) >>> df_heavy = df_light.pandas() >>> sub2 = df_heavy.take(indices) >>> assert np.all(sub1 == sub2)
- extend(other)[source]¶
Extend
selfinplace using another dataframe array- Parameters:
other (DataFrameLight | dict[str, Sequence]) – values to concat to end of this object
Note
Not part of the pandas API
Example
>>> self = DataFrameLight(columns=['foo', 'bar']) >>> other = {'foo': [0], 'bar': [1]} >>> self.extend(other) >>> assert len(self) == 1
- groupby(by=None, *args, **kwargs)[source]¶
Group rows by the value of a column. Unlike pandas this simply returns a zip object. To ensure compatiability call list on the result of groupby.
- Parameters:
by (str) – column name to group by
*args – if specified, the dataframe is coerced to pandas
*kwargs – if specified, the dataframe is coerced to pandas
Example
>>> df_light = DataFrameLight._demodata(num=7) >>> res1 = list(df_light.groupby('bar')) >>> # xdoctest: +REQUIRES(module:pandas) >>> df_heavy = df_light.pandas() >>> res2 = list(df_heavy.groupby('bar')) >>> assert len(res1) == len(res2) >>> assert all([np.all(a[1] == b[1]) for a, b in zip(res1, res2)])
- rename(mapper=None, columns=None, axis=None, inplace=False)[source]¶
Rename the columns (index renaming is not supported)
Example
>>> df_light = DataFrameLight._demodata(num=7) >>> mapper = {'foo': 'fi'} >>> res1 = df_light.rename(columns=mapper) >>> res3 = df_light.rename(mapper, axis=1) >>> # xdoctest: +REQUIRES(module:pandas) >>> df_heavy = df_light.pandas() >>> res2 = df_heavy.rename(columns=mapper) >>> res4 = df_heavy.rename(mapper, axis=1) >>> assert np.all(res1 == res2) >>> assert np.all(res3 == res2) >>> assert np.all(res3 == res4)
- iterrows()[source]¶
Iterate over rows as (index, Dict) pairs.
- Yields:
Tuple[int, Dict] – the index and a dictionary representing a row
Example
>>> from kwarray.dataframe_light import * # NOQA >>> self = DataFrameLight._demodata(num=3) >>> print(ub.urepr(list(self.iterrows()), sort=1)) [ (0, {'bar': 0, 'baz': 2.73, 'foo': 0}), (1, {'bar': 1, 'baz': 2.73, 'foo': 0}), (2, {'bar': 2, 'baz': 2.73, 'foo': 0}), ]
Benchmark
>>> # xdoc: +REQUIRES(--bench) >>> from kwarray.dataframe_light import * # NOQA >>> import ubelt as ub >>> df_light = DataFrameLight._demodata(num=1000) >>> df_heavy = df_light.pandas() >>> ti = ub.Timerit(21, bestof=3, verbose=2, unit='ms') >>> ti.reset('light').call(lambda: list(df_light.iterrows())) >>> ti.reset('heavy').call(lambda: list(df_heavy.iterrows())) >>> # xdoctest: +IGNORE_WANT Timed light for: 21 loops, best of 3 time per loop: best=0.834 ms, mean=0.850 ± 0.0 ms Timed heavy for: 21 loops, best of 3 time per loop: best=45.007 ms, mean=45.633 ± 0.5 ms
- class kwarray.FlatIndexer(lens)[source]¶
Bases:
NiceReprCreates a flat “view” of a jagged nested indexable object. Only supports one offset level.
- Parameters:
lens (List[int]) – a list of the lengths of the nested objects.
Doctest
>>> self = FlatIndexer([1, 2, 3]) >>> len(self) >>> self.unravel(4) >>> self.ravel(2, 1)
- classmethod fromlist(items)[source]¶
Convenience method to create a
FlatIndexerfrom the list of items itself instead of the array of lengths.- Parameters:
items (List[list]) – a list of the lists you want to flat index over
- Returns:
FlatIndexer
- unravel(index)[source]¶
- Parameters:
index (int | List[int]) – raveled index
- Returns:
outer and inner indices
- Return type:
Example
>>> import kwarray >>> rng = kwarray.ensure_rng(0) >>> items = [rng.rand(rng.randint(0, 10)) for _ in range(10)] >>> self = kwarray.FlatIndexer.fromlist(items) >>> index = np.arange(0, len(self)) >>> outer, inner = self.unravel(index) >>> recon = self.ravel(outer, inner) >>> # This check is only possible because index is an arange >>> check1 = np.hstack(list(map(sorted, kwarray.group_indices(outer)[1]))) >>> check2 = np.hstack(kwarray.group_consecutive_indices(inner)) >>> assert np.all(check1 == index) >>> assert np.all(check2 == index) >>> assert np.all(index == recon)
- exception kwarray.NoSupportError[source]¶
Bases:
RuntimeError
- class kwarray.RunningStats(nan_policy='omit', check_weights=True, **kwargs)[source]¶
Bases:
NiceReprTrack mean, std, min, and max values over time with constant memory.
Dynamically records per-element array statistics and can summarized them per-element, across channels, or globally.
Todo
[ ] This may need a few API tweaks and good documentation
Example
>>> import kwarray >>> run = kwarray.RunningStats() >>> ch1 = np.array([[0, 1], [3, 4]]) >>> ch2 = np.zeros((2, 2)) >>> img = np.dstack([ch1, ch2]) >>> run.update(np.dstack([ch1, ch2])) >>> run.update(np.dstack([ch1 + 1, ch2])) >>> run.update(np.dstack([ch1 + 2, ch2])) >>> # No marginalization >>> print('current-ave = ' + ub.urepr(run.summarize(axis=ub.NoParam), nl=2, precision=3)) >>> # Average over channels (keeps spatial dims separate) >>> print('chann-ave(k=1) = ' + ub.urepr(run.summarize(axis=0), nl=2, precision=3)) >>> print('chann-ave(k=0) = ' + ub.urepr(run.summarize(axis=0, keepdims=0), nl=2, precision=3)) >>> # Average over spatial dims (keeps channels separate) >>> print('spatial-ave(k=1) = ' + ub.urepr(run.summarize(axis=(1, 2)), nl=2, precision=3)) >>> print('spatial-ave(k=0) = ' + ub.urepr(run.summarize(axis=(1, 2), keepdims=0), nl=2, precision=3)) >>> # Average over all dims >>> print('alldim-ave(k=1) = ' + ub.urepr(run.summarize(axis=None), nl=2, precision=3)) >>> print('alldim-ave(k=0) = ' + ub.urepr(run.summarize(axis=None, keepdims=0), nl=2, precision=3))
- Parameters:
- nan_policy (str) – indicates how we will handle nan values
if “omit” - set weights of nan items to zero.
if “propogate” - propogate nans.
if “raise” - then raise a ValueError if nans are given.
- check_weights (bool):
if True, we check the weights for zeros (which can also implicitly occur when data has nans). Disabling this check will result in faster computation, but it is your responsibility to ensure all data passed to update is valid.
- property shape¶
- update_many(data, weights=1)[source]¶
Assumes first data axis represents multiple observations
Example
>>> import kwarray >>> rng = kwarray.ensure_rng(0) >>> run = kwarray.RunningStats() >>> data = rng.randn(1, 2, 3) >>> run.update_many(data) >>> print(run.current()) >>> data = rng.randn(2, 2, 3) >>> run.update_many(data) >>> print(run.current()) >>> data = rng.randn(3, 2, 3) >>> run.update_many(data) >>> print(run.current()) >>> run.update_many(1000) >>> print(run.current()) >>> assert np.all(run.current()['n'] == 7)
Example
>>> import kwarray >>> rng = kwarray.ensure_rng(0) >>> run = kwarray.RunningStats() >>> data = rng.randn(1, 2, 3) >>> run.update_many(data.ravel()) >>> print(run.current()) >>> data = rng.randn(2, 2, 3) >>> run.update_many(data.ravel()) >>> print(run.current()) >>> data = rng.randn(3, 2, 3) >>> run.update_many(data.ravel()) >>> print(run.current()) >>> run.update_many(1000) >>> print(run.current()) >>> assert np.all(run.current()['n'] == 37)
- update(data, weights=1)[source]¶
Updates statistics across all data dimensions on a per-element basis
Example
>>> import kwarray >>> data = np.full((7, 5), fill_value=1.3) >>> weights = np.ones((7, 5), dtype=np.float32) >>> run = kwarray.RunningStats() >>> run.update(data, weights=1) >>> run.update(data, weights=weights) >>> rng = np.random >>> weights[rng.rand(*weights.shape) > 0.5] = 0 >>> run.update(data, weights=weights)
Example
>>> import kwarray >>> run = kwarray.RunningStats() >>> data = np.array([[1, np.nan, np.nan], [0, np.nan, 1.]]) >>> run.update(data) >>> print('current = {}'.format(ub.urepr(run.current(), nl=1))) >>> print('summary(axis=None) = {}'.format(ub.urepr(run.summarize(), nl=1))) >>> print('summary(axis=1) = {}'.format(ub.urepr(run.summarize(axis=1), nl=1))) >>> print('summary(axis=0) = {}'.format(ub.urepr(run.summarize(axis=0), nl=1))) >>> data = np.array([[2, 0, 1], [0, 1, np.nan]]) >>> run.update(data) >>> data = np.array([[3, 1, 1], [0, 1, np.nan]]) >>> run.update(data) >>> data = np.array([[4, 1, 1], [0, 1, 1.]]) >>> run.update(data) >>> print('----') >>> print('current = {}'.format(ub.urepr(run.current(), nl=1))) >>> print('summary(axis=None) = {}'.format(ub.urepr(run.summarize(), nl=1))) >>> print('summary(axis=1) = {}'.format(ub.urepr(run.summarize(axis=1), nl=1))) >>> print('summary(axis=0) = {}'.format(ub.urepr(run.summarize(axis=0), nl=1)))
- summarize(axis=None, keepdims=True)[source]¶
Compute summary statistics across a one or more dimension
- Parameters:
axis (int | List[int] | None | NoParamType) – axis or axes to summarize over, if None, all axes are summarized. if ub.NoParam, no axes are summarized the current result is returned.
keepdims (bool, default=True) – if False removes the dimensions that are summarized over
- Returns:
containing minimum, maximum, mean, std, etc..
- Return type:
Dict
- Raises:
NoSupportError – if update was never called with valid data
Example
>>> # Test to make sure summarize works across different shapes >>> base = np.array([1, 1, 1, 1, 0, 0, 0, 1]) >>> run0 = RunningStats() >>> for _ in range(3): >>> run0.update(base.reshape(8, 1)) >>> run1 = RunningStats() >>> for _ in range(3): >>> run1.update(base.reshape(4, 2)) >>> run2 = RunningStats() >>> for _ in range(3): >>> run2.update(base.reshape(2, 2, 2)) >>> # >>> # Summarizing over everything should be exactly the same >>> s0N = run0.summarize(axis=None, keepdims=0) >>> s1N = run1.summarize(axis=None, keepdims=0) >>> s2N = run2.summarize(axis=None, keepdims=0) >>> #assert ub.util_indexable.indexable_allclose(s0N, s1N, rel_tol=0.0, abs_tol=0.0) >>> #assert ub.util_indexable.indexable_allclose(s1N, s2N, rel_tol=0.0, abs_tol=0.0) >>> assert s0N['mean'] == 0.625
- class kwarray.SlidingWindow(shape, window, overlap=None, stride=None, keepbound=False, allow_overshoot=False)[source]¶
Bases:
NiceReprSlide a window of a certain shape over an array with a larger shape.
This can be used for iterating over a grid of sub-regions of 2d-images, 3d-volumes, or any n-dimensional array.
Yields slices of shape window that can be used to index into an array with shape shape via numpy / torch fancy indexing. This allows for fast fast iteration over subregions of a larger image. Because we generate a grid-basis using only shapes, the larger image does not need to be in memory as long as its width/height/depth/etc…
- Parameters:
shape (Tuple[int, …]) – shape of source array to slide across.
window (Tuple[int, …]) – shape of window that will be slid over the larger image.
overlap (float, default=0) – a number between 0 and 1 indicating the fraction of overlap that parts will have. Specifying this is mutually exclusive with stride. Must be 0 <= overlap < 1.
stride (int, default=None) – the number of cells (pixels) moved on each step of the window. Mutually exclusive with overlap.
keepbound (bool, default=False) – if True, a non-uniform stride will be taken to ensure that the right / bottom of the image is returned as a slice if needed. Such a slice will not obey the overlap constraints. (Defaults to False)
allow_overshoot (bool, default=False) – if False, we will raise an error if the window doesn’t slide perfectly over the input shape.
- Variables:
strides (basis_shape - shape of the grid corresponding to the number of) – the sliding window will take.
dimension (basis_slices - slices that will be taken in every) –
- Yields:
Tuple[slice, …] –
- slices used for numpy indexing, the number of slices
in the tuple
Note
For each dimension, we generate a basis (which defines a grid), and we slide over that basis.
Todo
- [ ] have an option that is allowed to go outside of the window bounds
on the right and bottom when the slider overshoots.
Example
>>> from kwarray.util_slider import * # NOQA >>> shape = (10, 10) >>> window = (5, 5) >>> self = SlidingWindow(shape, window) >>> for i, index in enumerate(self): >>> print('i={}, index={}'.format(i, index)) i=0, index=(slice(0, 5, None), slice(0, 5, None)) i=1, index=(slice(0, 5, None), slice(5, 10, None)) i=2, index=(slice(5, 10, None), slice(0, 5, None)) i=3, index=(slice(5, 10, None), slice(5, 10, None))
Example
>>> from kwarray.util_slider import * # NOQA >>> shape = (16, 16) >>> window = (4, 4) >>> self = SlidingWindow(shape, window, overlap=(.5, .25)) >>> print('self.stride = {!r}'.format(self.stride)) self.stride = [2, 3] >>> list(ub.chunks(self.grid, 5)) [[(0, 0), (0, 1), (0, 2), (0, 3), (0, 4)], [(1, 0), (1, 1), (1, 2), (1, 3), (1, 4)], [(2, 0), (2, 1), (2, 2), (2, 3), (2, 4)], [(3, 0), (3, 1), (3, 2), (3, 3), (3, 4)], [(4, 0), (4, 1), (4, 2), (4, 3), (4, 4)], [(5, 0), (5, 1), (5, 2), (5, 3), (5, 4)], [(6, 0), (6, 1), (6, 2), (6, 3), (6, 4)]]
Example
>>> # Test shapes that dont fit >>> # When the window is bigger than the shape, the left-aligned slices >>> # are returend. >>> self = SlidingWindow((3, 3), (12, 12), allow_overshoot=True, keepbound=True) >>> print(list(self)) [(slice(0, 12, None), slice(0, 12, None))] >>> print(list(SlidingWindow((3, 3), None, allow_overshoot=True, keepbound=True))) [(slice(0, 3, None), slice(0, 3, None))] >>> print(list(SlidingWindow((3, 3), (None, 2), allow_overshoot=True, keepbound=True))) [(slice(0, 3, None), slice(0, 2, None)), (slice(0, 3, None), slice(1, 3, None))]
- _compute_stride(overlap, stride, shape, window)[source]¶
Ensures that stride hasoverlap the correct shape. If stride is not provided, compute stride from desired overlap.
- property grid¶
Generate indices into the “basis” slice for each dimension. This enumerates the nd indices of the grid.
- Yields:
Tuple[int, …]
- property slices¶
Generate slices for each window (equivalent to iter(self))
Example
>>> shape = (220, 220) >>> window = (10, 10) >>> self = SlidingWindow(shape, window, stride=5) >>> list(self)[41:45] [(slice(0, 10, None), slice(205, 215, None)), (slice(0, 10, None), slice(210, 220, None)), (slice(5, 15, None), slice(0, 10, None)), (slice(5, 15, None), slice(5, 15, None))] >>> print('self.overlap = {!r}'.format(self.overlap)) self.overlap = [0.5, 0.5]
- property centers¶
Generate centers of each window
- Yields:
Tuple[float, …] – the center coordinate of the slice
Example
>>> shape = (4, 4) >>> window = (3, 3) >>> self = SlidingWindow(shape, window, stride=1) >>> list(zip(self.centers, self.slices)) [((1.0, 1.0), (slice(0, 3, None), slice(0, 3, None))), ((1.0, 2.0), (slice(0, 3, None), slice(1, 4, None))), ((2.0, 1.0), (slice(1, 4, None), slice(0, 3, None))), ((2.0, 2.0), (slice(1, 4, None), slice(1, 4, None)))] >>> shape = (3, 3) >>> window = (2, 2) >>> self = SlidingWindow(shape, window, stride=1) >>> list(zip(self.centers, self.slices)) [((0.5, 0.5), (slice(0, 2, None), slice(0, 2, None))), ((0.5, 1.5), (slice(0, 2, None), slice(1, 3, None))), ((1.5, 0.5), (slice(1, 3, None), slice(0, 2, None))), ((1.5, 1.5), (slice(1, 3, None), slice(1, 3, None)))]
- class kwarray.Stitcher(shape, device='numpy', dtype='float32', nan_policy='propogate')[source]¶
Bases:
NiceReprStitches multiple possibly overlapping slices into a larger array.
This is used to invert the SlidingWindow. For semenatic segmentation the patches are probability chips. Overlapping chips are averaged together.
- SeeAlso:
kwarray.RunningStats- similarly performs running means, butcan also track other statistics.
Example
>>> from kwarray.util_slider import * # NOQA >>> import sys >>> # Build a high resolution image and slice it into chips >>> highres = np.random.rand(5, 200, 200).astype(np.float32) >>> target_shape = (1, 50, 50) >>> slider = SlidingWindow(highres.shape, target_shape, overlap=(0, .5, .5)) >>> # Show how Sticher can be used to reconstruct the original image >>> stitcher = Stitcher(slider.input_shape) >>> for sl in list(slider): ... chip = highres[sl] ... stitcher.add(sl, chip) >>> assert stitcher.weights.max() == 4, 'some parts should be processed 4 times' >>> recon = stitcher.finalize()
Example
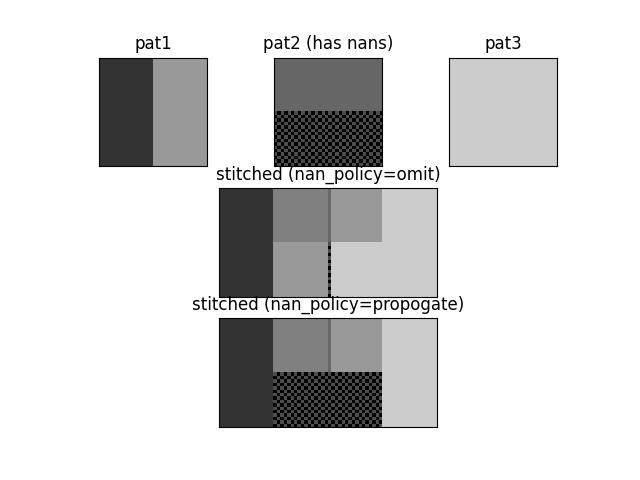
>>> from kwarray.util_slider import * # NOQA >>> import sys >>> # Demo stitching 3 patterns where one has nans >>> pat1 = np.full((32, 32), fill_value=0.2) >>> pat2 = np.full((32, 32), fill_value=0.4) >>> pat3 = np.full((32, 32), fill_value=0.8) >>> pat1[:, 16:] = 0.6 >>> pat2[16:, :] = np.nan >>> # Test with nan_policy=omit >>> stitcher = Stitcher(shape=(32, 64), nan_policy='omit') >>> stitcher[0:32, 0:32](pat1) >>> stitcher[0:32, 16:48](pat2) >>> stitcher[0:32, 33:64](pat3[:, 1:]) >>> final1 = stitcher.finalize() >>> # Test without nan_policy=propogate >>> stitcher = Stitcher(shape=(32, 64), nan_policy='propogate') >>> stitcher[0:32, 0:32](pat1) >>> stitcher[0:32, 16:48](pat2) >>> stitcher[0:32, 33:64](pat3[:, 1:]) >>> final2 = stitcher.finalize() >>> # Checks >>> assert np.isnan(final1).sum() == 16, 'only should contain nan where no data was stiched' >>> assert np.isnan(final2).sum() == 512, 'should contain nan wherever a nan was stitched' >>> # xdoctest: +REQUIRES(--show) >>> # xdoctest: +REQUIRES(module:kwplot) >>> import kwplot >>> import kwimage >>> kwplot.autompl() >>> kwplot.imshow(pat1, title='pat1', pnum=(3, 3, 1)) >>> kwplot.imshow(kwimage.nodata_checkerboard(pat2, square_shape=1), title='pat2 (has nans)', pnum=(3, 3, 2)) >>> kwplot.imshow(pat3, title='pat3', pnum=(3, 3, 3)) >>> kwplot.imshow(kwimage.nodata_checkerboard(final1, square_shape=1), title='stitched (nan_policy=omit)', pnum=(3, 1, 2)) >>> kwplot.imshow(kwimage.nodata_checkerboard(final2, square_shape=1), title='stitched (nan_policy=propogate)', pnum=(3, 1, 3))
Example
>>> # Example of weighted stitching >>> # xdoctest: +REQUIRES(module:kwimage) >>> from kwarray.util_slider import * # NOQA >>> import kwimage >>> import kwarray >>> import sys >>> data = kwimage.Mask.demo().data.astype(np.float32) >>> data_dims = data.shape >>> window_dims = (8, 8) >>> # We are going to slide a window over the data, do some processing >>> # and then stitch it all back together. There are a few ways we >>> # can do it. Lets demo the params. >>> basis = { >>> # Vary the overlap of the slider >>> 'overlap': (0, 0.5, .9), >>> # Vary if we are using weighted stitching or not >>> 'weighted': ['none', 'gauss'], >>> 'keepbound': [True, False] >>> } >>> results = [] >>> gauss_weights = kwimage.gaussian_patch(window_dims) >>> gauss_weights = kwimage.normalize(gauss_weights) >>> for params in ub.named_product(basis): >>> if params['weighted'] == 'none': >>> weights = None >>> elif params['weighted'] == 'gauss': >>> weights = gauss_weights >>> # Build the slider and stitcher >>> slider = kwarray.SlidingWindow( >>> data_dims, window_dims, overlap=params['overlap'], >>> allow_overshoot=True, >>> keepbound=params['keepbound']) >>> stitcher = kwarray.Stitcher(data_dims) >>> # Loop over the regions >>> for sl in list(slider): >>> chip = data[sl] >>> # This is our dummy function for thie example. >>> predicted = np.ones_like(chip) * chip.sum() / chip.size >>> stitcher.add(sl, predicted, weight=weights) >>> final = stitcher.finalize() >>> results.append({ >>> 'final': final, >>> 'params': params, >>> }) >>> # xdoctest: +REQUIRES(--show) >>> # xdoctest: +REQUIRES(module:kwplot) >>> import kwplot >>> kwplot.autompl() >>> pnum_ = kwplot.PlotNums(nCols=3, nSubplots=len(results) + 2) >>> kwplot.imshow(data, pnum=pnum_(), title='input image') >>> kwplot.imshow(gauss_weights, pnum=pnum_(), title='Gaussian weights') >>> pnum_() >>> for result in results: >>> param_key = ub.urepr(result['params'], compact=1) >>> final = result['final'] >>> canvas = kwarray.normalize(final) >>> canvas = kwimage.fill_nans_with_checkers(canvas) >>> kwplot.imshow(canvas, pnum=pnum_(), title=param_key)

- Parameters:
shape (tuple) – dimensions of the large image that will be created from the smaller pixels or patches.
device (str | int | torch.device) – default is ‘numpy’, but if given as a torch device, then underlying operations will be done with torch tensors instead.
dtype (str) – the datatype to use in the underlying accumulator.
nan_policy (str) – if omit, check for nans and convert any to zero weight items in stitching.
- add(indices, patch, weight=None)[source]¶
Incorporate a new (possibly overlapping) patch or pixel using a weighted sum.
- Parameters:
indices (slice | tuple | None) – typically a Tuple[slice] of pixels or a single pixel, but this can be any numpy fancy index.
patch (ndarray) – data to patch into the bigger image.
weight (float | ndarray) – weight of this patch (default to 1.0)
- kwarray.apply_embedded_slice(data, data_slice, extra_padding, **padkw)[source]¶
Apply a precomputed embedded slice.
This is used as a subroutine in padded_slice.
- Parameters:
data (ndarray) – data to slice
data_slice (Tuple[slice])
extra_padding (Tuple[slice])
- Returns:
ndarray
- kwarray.apply_grouping(items, groupxs, axis=0)[source]¶
Applies grouping from group_indicies.
Typically used in conjunction with
group_indices().- Parameters:
items (NDArray) – items to group
groupxs (List[NDArray[None, Int]]) – groups of indices
axis (None|int, default=0)
- Returns:
grouped items
- Return type:
List[NDArray]
Example
>>> # xdoctest: +IGNORE_WHITESPACE >>> idx_to_groupid = np.array([2, 1, 2, 1, 2, 1, 2, 3, 3, 3, 3]) >>> items = np.array([1, 8, 5, 5, 8, 6, 7, 5, 3, 0, 9]) >>> (keys, groupxs) = group_indices(idx_to_groupid) >>> grouped_items = apply_grouping(items, groupxs) >>> result = str(grouped_items) >>> print(result) [array([8, 5, 6]), array([1, 5, 8, 7]), array([5, 3, 0, 9])]
- kwarray.arglexmax(keys, multi=False)[source]¶
Find the index of the maximum element in a sequence of keys.
- Parameters:
keys (tuple) – a k-tuple of k N-dimensional arrays. Like np.lexsort the last key in the sequence is used for the primary sort order, the second-to-last key for the secondary sort order, and so on.
multi (bool) – if True, returns all indices that share the max value
- Returns:
either the index or list of indices
- Return type:
int | NDArray[Any, Int]
Example
>>> k, N = 100, 100 >>> rng = np.random.RandomState(0) >>> keys = [(rng.rand(N) * N).astype(int) for _ in range(k)] >>> multi_idx = arglexmax(keys, multi=True) >>> idxs = np.lexsort(keys) >>> assert sorted(idxs[::-1][:len(multi_idx)]) == sorted(multi_idx)
- Benchark:
>>> import ubelt as ub >>> k, N = 100, 100 >>> rng = np.random >>> keys = [(rng.rand(N) * N).astype(int) for _ in range(k)] >>> for timer in ub.Timerit(100, bestof=10, label='arglexmax'): >>> with timer: >>> arglexmax(keys) >>> for timer in ub.Timerit(100, bestof=10, label='lexsort'): >>> with timer: >>> np.lexsort(keys)[-1]
- kwarray.argmaxima(arr, num, axis=None, ordered=True)[source]¶
Returns the top
nummaximum indicies.This can be significantly faster than using argsort.
- Parameters:
arr (NDArray) – input array
num (int) – number of maximum indices to return
axis (int | None) – axis to find maxima over. If None this is equivalent to using arr.ravel().
ordered (bool) – if False, returns the maximum elements in an arbitrary order, otherwise they are in decending order. (Setting this to false is a bit faster).
Todo
[ ] if num is None, return arg for all values equal to the maximum
- Returns:
NDArray
Example
>>> # Test cases with axis=None >>> arr = (np.random.rand(100) * 100).astype(int) >>> for num in range(0, len(arr) + 1): >>> idxs = argmaxima(arr, num) >>> idxs2 = argmaxima(arr, num, ordered=False) >>> assert np.all(arr[idxs] == np.array(sorted(arr)[::-1][:len(idxs)])), 'ordered=True must return in order' >>> assert sorted(idxs2) == sorted(idxs), 'ordered=False must return the right idxs, but in any order'
Example
>>> # Test cases with axis >>> arr = (np.random.rand(3, 5, 7) * 100).astype(int) >>> for axis in range(len(arr.shape)): >>> for num in range(0, len(arr) + 1): >>> idxs = argmaxima(arr, num, axis=axis) >>> idxs2 = argmaxima(arr, num, ordered=False, axis=axis) >>> assert idxs.shape[axis] == num >>> assert idxs2.shape[axis] == num
- kwarray.argminima(arr, num, axis=None, ordered=True)[source]¶
Returns the top
numminimum indicies.This can be significantly faster than using argsort.
- Parameters:
arr (NDArray) – input array
num (int) – number of minimum indices to return
axis (int|None) – axis to find minima over. If None this is equivalent to using arr.ravel().
ordered (bool) – if False, returns the minimum elements in an arbitrary order, otherwise they are in ascending order. (Setting this to false is a bit faster).
Example
>>> arr = (np.random.rand(100) * 100).astype(int) >>> for num in range(0, len(arr) + 1): >>> idxs = argminima(arr, num) >>> assert np.all(arr[idxs] == np.array(sorted(arr)[:len(idxs)])), 'ordered=True must return in order' >>> idxs2 = argminima(arr, num, ordered=False) >>> assert sorted(idxs2) == sorted(idxs), 'ordered=False must return the right idxs, but in any order'
Example
>>> # Test cases with axis >>> from kwarray.util_numpy import * # NOQA >>> arr = (np.random.rand(3, 5, 7) * 100).astype(int) >>> # make a unique array so we can check argmax consistency >>> arr = np.arange(3 * 5 * 7) >>> np.random.shuffle(arr) >>> arr = arr.reshape(3, 5, 7) >>> for axis in range(len(arr.shape)): >>> for num in range(0, len(arr) + 1): >>> idxs = argminima(arr, num, axis=axis) >>> idxs2 = argminima(arr, num, ordered=False, axis=axis) >>> print('idxs = {!r}'.format(idxs)) >>> print('idxs2 = {!r}'.format(idxs2)) >>> assert idxs.shape[axis] == num >>> assert idxs2.shape[axis] == num >>> # Check if argmin argrees with -argmax >>> idxs3 = argmaxima(-arr, num, axis=axis) >>> assert np.all(idxs3 == idxs)
Example
>>> arr = np.arange(20).reshape(4, 5) % 6 >>> argminima(arr, axis=1, num=2, ordered=False) >>> argminima(arr, axis=1, num=2, ordered=True) >>> argmaxima(-arr, axis=1, num=2, ordered=True) >>> argmaxima(-arr, axis=1, num=2, ordered=False)
- kwarray.atleast_nd(arr, n, front=False)[source]¶
View inputs as arrays with at least n dimensions.
- Parameters:
arr (ArrayLike) – An array-like object. Non-array inputs are converted to arrays. Arrays that already have n or more dimensions are preserved.
n (int) – number of dimensions to ensure
front (bool) – if True new dimensions are added to the front of the array. otherwise they are added to the back. Defaults to False.
- Returns:
An array with
a.ndim >= n. Copies are avoided where possible, and views with three or more dimensions are returned. For example, a 1-D array of shape(N,)becomes a view of shape(1, N, 1), and a 2-D array of shape(M, N)becomes a view of shape(M, N, 1).- Return type:
NDArray
See also
numpy.atleast_1d, numpy.atleast_2d, numpy.atleast_3d
Example
>>> n = 2 >>> arr = np.array([1, 1, 1]) >>> arr_ = atleast_nd(arr, n) >>> import ubelt as ub # NOQA >>> result = ub.urepr(arr_.tolist(), nl=0) >>> print(result) [[1], [1], [1]]
Example
>>> n = 4 >>> arr1 = [1, 1, 1] >>> arr2 = np.array(0) >>> arr3 = np.array([[[[[1]]]]]) >>> arr1_ = atleast_nd(arr1, n) >>> arr2_ = atleast_nd(arr2, n) >>> arr3_ = atleast_nd(arr3, n) >>> import ubelt as ub # NOQA >>> result1 = ub.urepr(arr1_.tolist(), nl=0) >>> result2 = ub.urepr(arr2_.tolist(), nl=0) >>> result3 = ub.urepr(arr3_.tolist(), nl=0) >>> result = '\n'.join([result1, result2, result3]) >>> print(result) [[[[1]]], [[[1]]], [[[1]]]] [[[[0]]]] [[[[[1]]]]]
Note
Extensive benchmarks are in kwarray/dev/bench_atleast_nd.py
These demonstrate that this function is statistically faster than the numpy variants, although the difference is small. On average this function takes 480ns versus numpy which takes 790ns.
- kwarray.boolmask(indices, shape=None)[source]¶
Constructs an array of booleans where an item is True if its position is in
indicesotherwise it is False. This can be viewed as the inverse ofnumpy.where().- Parameters:
indices (NDArray) – list of integer indices
shape (int | tuple) – length of the returned list. If not specified the minimal possible shape to incoporate all the indices is used. In general, it is best practice to always specify this argument.
- Returns:
mask - mask[idx] is True if idx in indices
- Return type:
NDArray[Any, Int]
Example
>>> indices = [0, 1, 4] >>> mask = boolmask(indices, shape=6) >>> assert np.all(mask == [True, True, False, False, True, False]) >>> mask = boolmask(indices) >>> assert np.all(mask == [True, True, False, False, True])
Example
>>> import kwarray >>> import ubelt as ub # NOQA >>> indices = np.array([(0, 0), (1, 1), (2, 1)]) >>> shape = (3, 3) >>> mask = kwarray.boolmask(indices, shape) >>> result = ub.urepr(mask, with_dtype=0) >>> print(result) np.array([[ True, False, False], [False, True, False], [False, True, False]])
- kwarray.dtype_info(dtype)[source]¶
Lookup datatype information
- Parameters:
dtype (type) – a numpy, torch, or python numeric data type
- Returns:
an iinfo of finfo structure depending on the input type.
- Return type:
numpy.iinfo | numpy.finfo | torch.iinfo | torch.finfo
References
..[DtypeNotes] https://higra.readthedocs.io/en/stable/_modules/higra/hg_utils.html#dtype_info
Example
>>> from kwarray.arrayapi import * # NOQA >>> try: >>> import torch >>> except ImportError: >>> torch = None >>> results = [] >>> results += [dtype_info(float)] >>> results += [dtype_info(int)] >>> results += [dtype_info(complex)] >>> results += [dtype_info(np.float32)] >>> results += [dtype_info(np.int32)] >>> results += [dtype_info(np.uint32)] >>> if hasattr(np, 'complex256'): >>> results += [dtype_info(np.complex256)] >>> if torch is not None: >>> results += [dtype_info(torch.float32)] >>> results += [dtype_info(torch.int64)] >>> results += [dtype_info(torch.complex64)] >>> for info in results: >>> print('info = {!r}'.format(info)) >>> for info in results: >>> print('info.bits = {!r}'.format(info.bits))
- kwarray.embed_slice(slices, data_dims, pad=None)[source]¶
Embeds a “padded-slice” inside known data dimension.
Returns the valid data portion of the slice with extra padding for regions outside of the available dimension.
Given a slices for each dimension, image dimensions, and a padding get the corresponding slice from the image and any extra padding needed to achieve the requested window size.
Todo
[ ] Add the option to return the inverse slice
- Parameters:
slices (Tuple[slice, …]) – a tuple of slices for to apply to data data dimension.
data_dims (Tuple[int, …]) – n-dimension data sizes (e.g. 2d height, width)
pad (int | List[int | Tuple[int, int]]) – extra pad applied to (start / end) / (both) sides of each slice dim
- Returns:
- data_slice - Tuple[slice] a slice that can be applied to an array
with with shape data_dims. This slice will not correspond to the full window size if the requested slice is out of bounds.
- extra_padding - extra padding needed after slicing to achieve
the requested window size.
- Return type:
Tuple
Example
>>> # Case where slice is inside the data dims on left edge >>> import kwarray >>> slices = (slice(0, 10), slice(0, 10)) >>> data_dims = [300, 300] >>> pad = [10, 5] >>> a, b = kwarray.embed_slice(slices, data_dims, pad) >>> print('data_slice = {!r}'.format(a)) >>> print('extra_padding = {!r}'.format(b)) data_slice = (slice(0, 20, None), slice(0, 15, None)) extra_padding = [(10, 0), (5, 0)]
Example
>>> # Case where slice is bigger than the image >>> import kwarray >>> slices = (slice(-10, 400), slice(-10, 400)) >>> data_dims = [300, 300] >>> pad = [10, 5] >>> a, b = kwarray.embed_slice(slices, data_dims, pad) >>> print('data_slice = {!r}'.format(a)) >>> print('extra_padding = {!r}'.format(b)) data_slice = (slice(0, 300, None), slice(0, 300, None)) extra_padding = [(20, 110), (15, 105)]
Example
>>> # Case where slice is inside than the image >>> import kwarray >>> slices = (slice(10, 40), slice(10, 40)) >>> data_dims = [300, 300] >>> pad = None >>> a, b = kwarray.embed_slice(slices, data_dims, pad) >>> print('data_slice = {!r}'.format(a)) >>> print('extra_padding = {!r}'.format(b)) data_slice = (slice(10, 40, None), slice(10, 40, None)) extra_padding = [(0, 0), (0, 0)]
Example
>>> # Test error cases >>> import kwarray >>> import pytest >>> slices = (slice(0, 40), slice(10, 40)) >>> data_dims = [300, 300] >>> with pytest.raises(ValueError): >>> kwarray.embed_slice(slices, data_dims[0:1]) >>> with pytest.raises(ValueError): >>> kwarray.embed_slice(slices[0:1], data_dims) >>> with pytest.raises(ValueError): >>> kwarray.embed_slice(slices, data_dims, pad=[(1, 1)]) >>> with pytest.raises(ValueError): >>> kwarray.embed_slice(slices, data_dims, pad=[1])
- kwarray.ensure_rng(rng=None, api='numpy')[source]¶
Coerces input into a random number generator.
This function is useful for ensuring that your code uses a controlled internal random state that is independent of other modules.
If the input is None, then a global random state is returned.
If the input is a numeric value, then that is used as a seed to construct a random state.
If the input is a random number generator, then another random number generator with the same state is returned. Depending on the api, this random state is either return as-is, or used to construct an equivalent random state with the requested api.
- Parameters:
rng (int | float | None | numpy.random.RandomState | random.Random) – if None, then defaults to the global rng. Otherwise this can be an integer or a RandomState class. Defaults to the global random.
api (str) – specify the type of random number generator to use. This can either be ‘numpy’ for a
numpy.random.RandomStateobject or ‘python’ for arandom.Randomobject. Defaults to numpy.
- Returns:
rng - either a numpy or python random number generator, depending on the setting of
api.- Return type:
Example
>>> rng = ensure_rng(None) >>> ensure_rng(0).randint(0, 1000) 684 >>> ensure_rng(np.random.RandomState(1)).randint(0, 1000) 37
Example
>>> num = 4 >>> print('--- Python as PYTHON ---') >>> py_rng = random.Random(0) >>> pp_nums = [py_rng.random() for _ in range(num)] >>> print(pp_nums) >>> print('--- Numpy as PYTHON ---') >>> np_rng = ensure_rng(random.Random(0), api='numpy') >>> np_nums = [np_rng.rand() for _ in range(num)] >>> print(np_nums) >>> print('--- Numpy as NUMPY---') >>> np_rng = np.random.RandomState(seed=0) >>> nn_nums = [np_rng.rand() for _ in range(num)] >>> print(nn_nums) >>> print('--- Python as NUMPY---') >>> py_rng = ensure_rng(np.random.RandomState(seed=0), api='python') >>> pn_nums = [py_rng.random() for _ in range(num)] >>> print(pn_nums) >>> assert np_nums == pp_nums >>> assert pn_nums == nn_nums
Example
>>> # Test that random modules can be coerced >>> import random >>> import numpy as np >>> ensure_rng(random, api='python') >>> ensure_rng(random, api='numpy') >>> ensure_rng(np.random, api='python') >>> ensure_rng(np.random, api='numpy')
- kwarray.equal_with_nan(a1, a2)[source]¶
Numpy has array_equal with
equal_nan=True, but this is elementwise- Parameters:
a1 (ArrayLike) – input array
a2 (ArrayLike) – input array
Example
>>> import kwarray >>> a1 = np.array([ >>> [np.nan, 0, np.nan], >>> [np.nan, 0, 0], >>> [np.nan, 1, 0], >>> [np.nan, 1, np.nan], >>> ]) >>> a2 = np.array([np.nan, 0, np.nan]) >>> flags = kwarray.equal_with_nan(a1, a2) >>> assert np.array_equal(flags, np.array([ >>> [ True, False, True], >>> [ True, False, False], >>> [ True, True, False], >>> [ True, True, True] >>> ]))
- kwarray.find_robust_normalizers(data, params='auto')[source]¶
Finds robust normalization statistics a set of scalar observations.
The idea is to estimate “fense” parameters: minimum and maximum values where anything under / above these values are likely outliers. For non-linear normalizaiton schemes we can also estimate an likely middle and extent of the data.
- Parameters:
data (ndarray) – a 1D numpy array where invalid data has already been removed
params (str | dict) – normalization params.
When passed as a dictionary valid params are:
- scaling (str):
This is the “mode” that will be used in the final normalization. Currently has no impact on the Defaults to ‘linear’. Can also be ‘sigmoid’.
- extrema (str):
The method for determening what the extrama are. Can be “quantile” for strict quantile clipping Can be “adaptive-quantile” for an IQR-like adjusted quantile method. Can be “tukey” or “IQR” for an exact IQR method.
low (float): This is the low quantile for likely inliers.
mid (float): This is the middle quantlie for likely inliers.
high (float): This is the high quantile for likely inliers.
Can be specified as a concise string.
- The string “auto” defaults to:
dict(extrema='adaptive-quantile', scaling='linear', low=0.01, mid=0.5, high=0.9).- The string “tukey” defaults to:
dict(extrema='tukey', scaling='linear').
- Returns:
normalization parameters that can be passed to
kwarray.normalize()containing the keys:type (str): which is always ‘normalize’
mode (str): the value of
params['scaling']min_val (float): the determined “robust” minimum inlier value.
max_val (float): the determined “robust” maximum inlier value.
- beta (float): the determined “robust” middle value for use in
non-linear normalizers.
- alpha (float): the determined “robust” extent value for use in
non-linear normalizers.
- Return type:
Note
The defaults and methods of this function are subject to change.
Todo
[ ] No (or minimal) Magic Numbers! Use first principles to deterimine defaults.
[ ] Probably a lot of literature on the subject.
[ ] https://www.tandfonline.com/doi/full/10.1080/02664763.2019.1671961
- [ ] This function is not possible to get right in every case
(probably can prove this with a NFL theroem), might be useful to allow the user to specify a “model” which is specific to some domain.
Example
>>> from kwarray.util_robust import * # NOQA >>> data = np.random.rand(100) >>> norm_params1 = find_robust_normalizers(data, params='auto') >>> norm_params2 = find_robust_normalizers(data, params={'low': 0, 'high': 1.0}) >>> norm_params3 = find_robust_normalizers(np.empty(0), params='auto') >>> print('norm_params1 = {}'.format(ub.urepr(norm_params1, nl=1))) >>> print('norm_params2 = {}'.format(ub.urepr(norm_params2, nl=1))) >>> print('norm_params3 = {}'.format(ub.urepr(norm_params3, nl=1)))
Example
>>> # xdoctest: +REQUIRES(module:scipy) >>> from kwarray.util_robust import * # NOQA >>> from kwarray.distributions import Mixture >>> import ubelt as ub >>> # A random mixture distribution for testing >>> data = Mixture.random(6).sample(3000)
- kwarray.generalized_logistic(x, floor=0, capacity=1, C=1, y_intercept=None, Q=None, growth=1, v=1)[source]¶
A generalization of the logistic / sigmoid functions that allows for flexible specification of S-shaped curve.
This is also known as a “Richards curve” [WikiRichardsCurve].
- Parameters:
x (NDArray) – input x coordinates
floor (float) – the lower (left) asymptote. (Also called
Ain some texts). Defaults to 0.capacity (float) – the carrying capacity. When C=1, this is the upper (right) asymptote. (Also called
Kin some texts). Defaults to 1.C (float) – Has influence on the upper asymptote. Defaults to 1. This is typically not modified.
y_intercept (float | None) – specify where the the y intercept is at x=0. Mutually exclusive with
Q.Q (float | None) – related to the value of the function at x=0. Mutually exclusive with
y_intercept. Defaults to 1.growth (float) – the growth rate (also calle
Bin some texts). Defaults to 1.v (float) – Positive number that influences near which asymptote the growth occurs. Defaults to 1.
- Returns:
the values for each input
- Return type:
NDArray
References
Example
>>> from kwarray.util_numpy import * # NOQA >>> # xdoctest: +REQUIRES(module:pandas) >>> import pandas as pd >>> import ubelt as ub >>> x = np.linspace(-3, 3, 30) >>> basis = { >>> # 'y_intercept': [0.1, 0.5, 0.8, -1], >>> # 'y_intercept': [0.1, 0.5, 0.8], >>> 'v': [0.5, 1.0, 2.0], >>> 'growth': [-1, 0, 2], >>> } >>> grid = list(ub.named_product(basis)) >>> datas = [] >>> for params in grid: >>> y = generalized_logistic(x, **params) >>> data = pd.DataFrame({'x': x, 'y': y}) >>> key = ub.urepr(params, compact=1) >>> data['key'] = key >>> for k, v in params.items(): >>> data[k] = v >>> datas.append(data) >>> all_data = pd.concat(datas).reset_index() >>> # xdoctest: +REQUIRES(--show) >>> # xdoctest: +REQUIRES(module:kwplot) >>> import kwplot >>> plt = kwplot.autoplt() >>> sns = kwplot.autosns() >>> plt.gca().cla() >>> sns.lineplot(data=all_data, x='x', y='y', hue='growth', size='v')
- kwarray.group_consecutive(arr, offset=1)[source]¶
Returns lists of consecutive values. Implementation inspired by [3].
- Parameters:
arr (NDArray) – array of ordered values
offset (float, default=1) – any two values separated by this offset are grouped. In the default case, when offset=1, this groups increasing values like: 0, 1, 2. When offset is 0 it groups consecutive values thta are the same, e.g.: 4, 4, 4.
- Returns:
a list of arrays that are the groups from the input
- Return type:
List[NDArray]
Note
This is equivalent (and faster) to using: apply_grouping(data, group_consecutive_indices(data))
References
Example
>>> arr = np.array([1, 2, 3, 5, 6, 7, 8, 9, 10, 15, 99, 100, 101]) >>> groups = group_consecutive(arr) >>> print('groups = {}'.format(list(map(list, groups)))) groups = [[1, 2, 3], [5, 6, 7, 8, 9, 10], [15], [99, 100, 101]] >>> arr = np.array([0, 0, 3, 0, 0, 7, 2, 3, 4, 4, 4, 1, 1]) >>> groups = group_consecutive(arr, offset=1) >>> print('groups = {}'.format(list(map(list, groups)))) groups = [[0], [0], [3], [0], [0], [7], [2, 3, 4], [4], [4], [1], [1]] >>> groups = group_consecutive(arr, offset=0) >>> print('groups = {}'.format(list(map(list, groups)))) groups = [[0, 0], [3], [0, 0], [7], [2], [3], [4, 4, 4], [1, 1]]
- kwarray.group_consecutive_indices(arr, offset=1)[source]¶
Returns lists of indices pointing to consecutive values
- Parameters:
arr (NDArray) – array of ordered values
offset (float, default=1) – any two values separated by this offset are grouped.
- Returns:
groupxs: a list of indices
- Return type:
List[NDArray]
SeeAlso:
Example
>>> arr = np.array([1, 2, 3, 5, 6, 7, 8, 9, 10, 15, 99, 100, 101]) >>> groupxs = group_consecutive_indices(arr) >>> print('groupxs = {}'.format(list(map(list, groupxs)))) groupxs = [[0, 1, 2], [3, 4, 5, 6, 7, 8], [9], [10, 11, 12]] >>> assert all(np.array_equal(a, b) for a, b in zip(group_consecutive(arr, 1), apply_grouping(arr, groupxs))) >>> arr = np.array([0, 0, 3, 0, 0, 7, 2, 3, 4, 4, 4, 1, 1]) >>> groupxs = group_consecutive_indices(arr, offset=1) >>> print('groupxs = {}'.format(list(map(list, groupxs)))) groupxs = [[0], [1], [2], [3], [4], [5], [6, 7, 8], [9], [10], [11], [12]] >>> assert all(np.array_equal(a, b) for a, b in zip(group_consecutive(arr, 1), apply_grouping(arr, groupxs))) >>> groupxs = group_consecutive_indices(arr, offset=0) >>> print('groupxs = {}'.format(list(map(list, groupxs)))) groupxs = [[0, 1], [2], [3, 4], [5], [6], [7], [8, 9, 10], [11, 12]] >>> assert all(np.array_equal(a, b) for a, b in zip(group_consecutive(arr, 0), apply_grouping(arr, groupxs)))
- kwarray.group_indices(idx_to_groupid, assume_sorted=False)[source]¶
Find unique items and the indices at which they appear in an array.
A common use case of this function is when you have a list of objects (often numeric but sometimes not) and an array of “group-ids” corresponding to that list of objects.
Using this function will return a list of indices that can be used in conjunction with
apply_grouping()to group the elements. This is most useful when you have many lists (think column-major data) corresponding to the group-ids.In cases where there is only one list of objects or knowing the indices doesn’t matter, then consider using func:group_items instead.
- Parameters:
idx_to_groupid (NDArray) – The input array, where each item is interpreted as a group id. For the fastest runtime, the input array must be numeric (ideally with integer types). If the type is non-numeric then the less efficient
ubelt.group_items()is used.assume_sorted (bool) – If the input array is sorted, then setting this to True will avoid an unnecessary sorting operation and improve efficiency. Defaults to False.
- Returns:
- (keys, groupxs) -
- keys (NDArray):
The unique elements of the input array in order
- groupxs (List[NDArray]):
Corresponding list of indexes. The i-th item is an array indicating the indices where the item
key[i]appeared in the input array.
- Return type:
Tuple[NDArray, List[NDArray]]
Example
>>> # xdoctest: +IGNORE_WHITESPACE >>> import kwarray >>> import ubelt as ub >>> idx_to_groupid = np.array([2, 1, 2, 1, 2, 1, 2, 3, 3, 3, 3]) >>> (keys, groupxs) = kwarray.group_indices(idx_to_groupid) >>> print('keys = ' + ub.urepr(keys, with_dtype=False)) >>> print('groupxs = ' + ub.urepr(groupxs, with_dtype=False)) keys = np.array([1, 2, 3]) groupxs = [ np.array([1, 3, 5]), np.array([0, 2, 4, 6]), np.array([ 7, 8, 9, 10]), ]
Example
>>> # xdoctest: +IGNORE_WHITESPACE >>> import kwarray >>> import ubelt as ub >>> # 2d arrays must be flattened before coming into this function so >>> # information is on the last axis >>> idx_to_groupid = np.array([[ 24], [ 129], [ 659], [ 659], [ 24], ... [659], [ 659], [ 822], [ 659], [ 659], [24]]).T[0] >>> (keys, groupxs) = kwarray.group_indices(idx_to_groupid) >>> # Different versions of numpy may produce different orderings >>> # so normalize these to make test output consistent >>> #[gxs.sort() for gxs in groupxs] >>> print('keys = ' + ub.urepr(keys, with_dtype=False)) >>> print('groupxs = ' + ub.urepr(groupxs, with_dtype=False)) keys = np.array([ 24, 129, 659, 822]) groupxs = [ np.array([ 0, 4, 10]), np.array([1]), np.array([2, 3, 5, 6, 8, 9]), np.array([7]), ]
Example
>>> # xdoctest: +IGNORE_WHITESPACE >>> import kwarray >>> import ubelt as ub >>> idx_to_groupid = np.array([True, True, False, True, False, False, True]) >>> (keys, groupxs) = kwarray.group_indices(idx_to_groupid) >>> print(ub.urepr(keys, with_dtype=False)) >>> print(ub.urepr(groupxs, with_dtype=False)) np.array([False, True]) [ np.array([2, 4, 5]), np.array([0, 1, 3, 6]), ]
Example
>>> # xdoctest: +IGNORE_WHITESPACE >>> import ubelt as ub >>> import kwarray >>> idx_to_groupid = [('a', 'b'), ('d', 'b'), ('a', 'b'), ('a', 'b')] >>> (keys, groupxs) = kwarray.group_indices(idx_to_groupid) >>> print(ub.urepr(keys, with_dtype=False)) >>> print(ub.urepr(groupxs, with_dtype=False)) [ ('a', 'b'), ('d', 'b'), ] [ np.array([0, 2, 3]), np.array([1]), ]
- kwarray.group_items(item_list, groupid_list, assume_sorted=False, axis=None)[source]¶
Groups a list of items by group id.
Works like
ubelt.group_items(), but with numpy optimizations. This can be quite a bit faster than usingitertools.groupby()[1] [2].In cases where there are many lists of items to group (think column-major data), consider using
group_indices()andapply_grouping()instead.- Parameters:
item_list (NDArray) – The input array of items to group. Extended typing
NDArray[Any, VT]groupid_list (NDArray) – Each item is an id corresponding to the item at the same position in
item_list. For the fastest runtime, the input array must be numeric (ideally with integer types). This list must be 1-dimensional. Extended typingNDArray[Any, KT]assume_sorted (bool) – If the input array is sorted, then setting this to True will avoid an unnecessary sorting operation and improve efficiency. Defaults to False.
axis (int | None) – Group along a particular axis in
itemsif it is n-dimensional.
- Returns:
mapping from groupids to corresponding items. Extended typing
Dict[KT, NDArray[Any, VT]].- Return type:
Dict[Any, NDArray]
References
Example
>>> from kwarray.util_groups import * # NOQA >>> items = np.array([0, 1, 2, 3, 4, 5, 6, 7, 1, 1]) >>> keys = np.array( [2, 2, 1, 1, 0, 1, 0, 1, 1, 1]) >>> grouped = group_items(items, keys) >>> print('grouped = ' + ub.urepr(grouped, nl=1, with_dtype=False, sort=1)) grouped = { 0: np.array([4, 6]), 1: np.array([2, 3, 5, 7, 1, 1]), 2: np.array([0, 1]), }
- kwarray.isect_flags(arr, other)[source]¶
Check which items in an array intersect with another set of items
- Parameters:
arr (NDArray) – items to check
other (Iterable) – items to check if they exist in arr
- Returns:
- booleans corresponding to arr indicating if any item in other
is also contained in other.
- Return type:
NDArray
Example
>>> arr = np.array([ >>> [1, 2, 3, 4], >>> [5, 6, 3, 4], >>> [1, 1, 3, 4], >>> ]) >>> other = np.array([1, 4, 6]) >>> mask = isect_flags(arr, other) >>> print(mask) [[ True False False True] [False True False True] [ True True False True]]
- kwarray.iter_reduce_ufunc(ufunc, arrs, out=None, default=None)[source]¶
constant memory iteration and reduction
Applys ufunc from left to right over the input arrays
- Parameters:
ufunc (Callable) – called on each pair of consecutive ndarrays
arrs (Iterator[NDArray]) – iterator of ndarrays
default (object) – return value when iterator is empty
- Returns:
if len(arrs) == 0, returns
defaultif len(arrs) == 1, returns arrs[0], if len(arrs) >= 2, returns ufunc(…ufunc(ufunc(arrs[0], arrs[1]), arrs[2]),…arrs[n-1])- Return type:
NDArray
Example
>>> arr_list = [ ... np.array([0, 1, 2, 3, 8, 9]), ... np.array([4, 1, 2, 3, 4, 5]), ... np.array([0, 5, 2, 3, 4, 5]), ... np.array([1, 1, 6, 3, 4, 5]), ... np.array([0, 1, 2, 7, 4, 5]) ... ] >>> memory = np.array([9, 9, 9, 9, 9, 9]) >>> gen_memory = memory.copy() >>> def arr_gen(arr_list, gen_memory): ... for arr in arr_list: ... gen_memory[:] = arr ... yield gen_memory >>> print('memory = %r' % (memory,)) >>> print('gen_memory = %r' % (gen_memory,)) >>> ufunc = np.maximum >>> res1 = iter_reduce_ufunc(ufunc, iter(arr_list), out=None) >>> res2 = iter_reduce_ufunc(ufunc, iter(arr_list), out=memory) >>> res3 = iter_reduce_ufunc(ufunc, arr_gen(arr_list, gen_memory), out=memory) >>> print('res1 = %r' % (res1,)) >>> print('res2 = %r' % (res2,)) >>> print('res3 = %r' % (res3,)) >>> print('memory = %r' % (memory,)) >>> print('gen_memory = %r' % (gen_memory,)) >>> assert np.all(res1 == res2) >>> assert np.all(res2 == res3)
- kwarray.maxvalue_assignment(value)[source]¶
Finds the maximum value assignment based on a NxM value matrix. Any pair with a non-positive value will not be assigned.
- Parameters:
value (ndarray) – NxM matrix, value[i, j] is the value of matching i and j
- Returns:
- tuple containing a list of assignment of rows
and columns, and the total value of the assignment.
- Return type:
CommandLine
xdoctest -m ~/code/kwarray/kwarray/algo_assignment.py maxvalue_assignment
Example
>>> # xdoctest: +REQUIRES(module:scipy) >>> # Costs to match item i in set1 with item j in set2. >>> value = np.array([ >>> [9, 2, 1, 3], >>> [4, 1, 5, 5], >>> [9, 9, 2, 4], >>> [-1, -1, -1, -1], >>> ]) >>> ret = maxvalue_assignment(value) >>> # Note, depending on the scipy version the assignment might change >>> # but the value should always be the same. >>> print('Total value: {}'.format(ret[1])) Total value: 23.0 >>> print('Assignment: {}'.format(ret[0])) # xdoc: +IGNORE_WANT Assignment: [(0, 0), (1, 3), (2, 1)]
>>> ret = maxvalue_assignment(np.array([[np.inf]])) >>> print('Assignment: {}'.format(ret[0])) >>> print('Total value: {}'.format(ret[1])) Assignment: [(0, 0)] Total value: inf
>>> ret = maxvalue_assignment(np.array([[0]])) >>> print('Assignment: {}'.format(ret[0])) >>> print('Total value: {}'.format(ret[1])) Assignment: [] Total value: 0
- kwarray.mincost_assignment(cost)[source]¶
Finds the minimum cost assignment based on a NxM cost matrix, subject to the constraint that each row can match at most one column and each column can match at most one row. Any pair with a cost of infinity will not be assigned.
- Parameters:
cost (ndarray) – NxM matrix, cost[i, j] is the cost to match i and j
- Returns:
- tuple containing a list of assignment of rows
and columns, and the total cost of the assignment.
- Return type:
CommandLine
xdoctest -m ~/code/kwarray/kwarray/algo_assignment.py mincost_assignment
Example
>>> # xdoctest: +REQUIRES(module:scipy) >>> # Costs to match item i in set1 with item j in set2. >>> cost = np.array([ >>> [9, 2, 1, 9], >>> [4, 1, 5, 5], >>> [9, 9, 2, 4], >>> ]) >>> ret = mincost_assignment(cost) >>> print('Assignment: {}'.format(ret[0])) >>> print('Total cost: {}'.format(ret[1])) Assignment: [(0, 2), (1, 1), (2, 3)] Total cost: 6
Example
>>> # xdoctest: +REQUIRES(module:scipy) >>> cost = np.array([ >>> [0, 0, 0, 0], >>> [4, 1, 5, -np.inf], >>> [9, 9, np.inf, 4], >>> [9, -2, np.inf, 4], >>> ]) >>> ret = mincost_assignment(cost) >>> print('Assignment: {}'.format(ret[0])) >>> print('Total cost: {}'.format(ret[1])) Assignment: [(0, 2), (1, 3), (2, 0), (3, 1)] Total cost: -inf
Example
>>> # xdoctest: +REQUIRES(module:scipy) >>> cost = np.array([ >>> [0, 0, 0, 0], >>> [4, 1, 5, -3], >>> [1, 9, np.inf, 0.1], >>> [np.inf, np.inf, np.inf, 100], >>> ]) >>> ret = mincost_assignment(cost) >>> print('Assignment: {}'.format(ret[0])) >>> print('Total cost: {}'.format(ret[1])) Assignment: [(0, 2), (1, 1), (2, 0), (3, 3)] Total cost: 102.0
- kwarray.mindist_assignment(vecs1, vecs2, p=2)[source]¶
Finds minimum cost assignment between two sets of D dimensional vectors.
- Parameters:
vecs1 (np.ndarray) – NxD array of vectors representing items in vecs1
vecs2 (np.ndarray) – MxD array of vectors representing items in vecs2
p (float) – L-p norm to use. Default is 2 (aka Eucliedean)
- Returns:
- tuple containing assignments of rows in vecs1 to
rows in vecs2, and the total distance between assigned pairs.
- Return type:
Note
Thin wrapper around mincost_assignment
CommandLine
xdoctest -m ~/code/kwarray/kwarray/algo_assignment.py mindist_assignment
CommandLine
xdoctest -m ~/code/kwarray/kwarray/algo_assignment.py mindist_assignment
Example
>>> # xdoctest: +REQUIRES(module:scipy) >>> # Rows are detections in img1, cols are detections in img2 >>> rng = np.random.RandomState(43) >>> vecs1 = rng.randint(0, 10, (5, 2)) >>> vecs2 = rng.randint(0, 10, (7, 2)) >>> ret = mindist_assignment(vecs1, vecs2) >>> print('Total error: {:.4f}'.format(ret[1])) Total error: 8.2361 >>> print('Assignment: {}'.format(ret[0])) # xdoc: +IGNORE_WANT Assignment: [(0, 0), (1, 3), (2, 5), (3, 2), (4, 6)]
- kwarray.normalize(arr, mode='linear', alpha=None, beta=None, out=None, min_val=None, max_val=None)[source]¶
Normalizes input values based on a specified scheme.
The default behavior is a linear normalization between 0.0 and 1.0 based on the min/max values of the input. Parameters can be specified to achieve more general constrat stretching or signal rebalancing. Implements the linear and sigmoid normalization methods described in [WikiNorm].
- Parameters:
arr (NDArray) – array to normalize, usually an image
out (NDArray | None) – output array. Note, that we will create an internal floating point copy for integer computations.
mode (str) – either linear or sigmoid.
alpha (float) – Only used if mode=sigmoid. Division factor (pre-sigmoid). If unspecified computed as:
max(abs(old_min - beta), abs(old_max - beta)) / 6.212606. Note this parameter is sensitive to if the input is a float or uint8 image.beta (float) – subtractive factor (pre-sigmoid). This should be the intensity of the most interesting bits of the image, i.e. bring them to the center (0) of the distribution. Defaults to
(max - min) / 2. Note this parameter is sensitive to if the input is a float or uint8 image.min_val – inputs lower than this minimum value are clipped
max_val – inputs higher than this maximum value are clipped.
- SeeAlso:
find_robust_normalizers()- determine robust parameters fornormalize to mitigate the effect of outliers.
robust_normalize()- finds and applies robust normalizationparameters
References
Example
>>> raw_f = np.random.rand(8, 8) >>> norm_f = normalize(raw_f)
>>> raw_f = np.random.rand(8, 8) * 100 >>> norm_f = normalize(raw_f) >>> assert isclose(norm_f.min(), 0) >>> assert isclose(norm_f.max(), 1)
>>> raw_u = (np.random.rand(8, 8) * 255).astype(np.uint8) >>> norm_u = normalize(raw_u)
Example
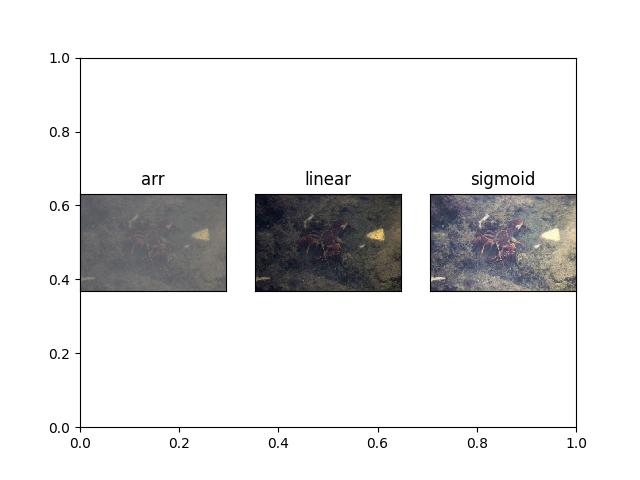
>>> # xdoctest: +REQUIRES(module:kwimage) >>> import kwimage >>> arr = kwimage.grab_test_image('lowcontrast') >>> arr = kwimage.ensure_float01(arr) >>> norms = {} >>> norms['arr'] = arr.copy() >>> norms['linear'] = normalize(arr, mode='linear') >>> # xdoctest: +REQUIRES(module:scipy) >>> norms['sigmoid'] = normalize(arr, mode='sigmoid') >>> # xdoctest: +REQUIRES(--show) >>> import kwplot >>> kwplot.autompl() >>> kwplot.figure(fnum=1, doclf=True) >>> pnum_ = kwplot.PlotNums(nSubplots=len(norms)) >>> for key, img in norms.items(): >>> kwplot.imshow(img, pnum=pnum_(), title=key)
Example
>>> # xdoctest: +REQUIRES(module:kwimage) >>> arr = np.array([np.inf]) >>> normalize(arr, mode='linear') >>> # xdoctest: +REQUIRES(module:scipy) >>> normalize(arr, mode='sigmoid') >>> # xdoctest: +REQUIRES(--show) >>> import kwplot >>> kwplot.autompl() >>> kwplot.figure(fnum=1, doclf=True) >>> pnum_ = kwplot.PlotNums(nSubplots=len(norms)) >>> for key, img in norms.items(): >>> kwplot.imshow(img, pnum=pnum_(), title=key)
Benchmark
>>> # Our method is faster than standard in-line implementations for >>> # uint8 and competative with in-line float32, in addition to being >>> # more concise and configurable. In 3.11 all inplace variants are >>> # faster. >>> # xdoctest: +REQUIRES(module:kwimage) >>> import timerit >>> import kwimage >>> import kwarray >>> ti = timerit.Timerit(1000, bestof=10, verbose=2, unit='ms') >>> arr = kwimage.grab_test_image('lowcontrast', dsize=(512, 512)) >>> # >>> arr = kwimage.ensure_float01(arr) >>> out = arr.copy() >>> for timer in ti.reset('inline_naive(float)'): >>> with timer: >>> (arr - arr.min()) / (arr.max() - arr.min()) >>> # >>> for timer in ti.reset('inline_faster(float)'): >>> with timer: >>> max_ = arr.max() >>> min_ = arr.min() >>> result = (arr - min_) / (max_ - min_) >>> # >>> for timer in ti.reset('kwarray.normalize(float)'): >>> with timer: >>> kwarray.normalize(arr) >>> # >>> for timer in ti.reset('kwarray.normalize(float, inplace)'): >>> with timer: >>> kwarray.normalize(arr, out=out) >>> # >>> arr = kwimage.ensure_uint255(arr) >>> out = arr.copy() >>> for timer in ti.reset('inline_naive(uint8)'): >>> with timer: >>> (arr - arr.min()) / (arr.max() - arr.min()) >>> # >>> for timer in ti.reset('inline_faster(uint8)'): >>> with timer: >>> max_ = arr.max() >>> min_ = arr.min() >>> result = (arr - min_) / (max_ - min_) >>> # >>> for timer in ti.reset('kwarray.normalize(uint8)'): >>> with timer: >>> kwarray.normalize(arr) >>> # >>> for timer in ti.reset('kwarray.normalize(uint8, inplace)'): >>> with timer: >>> kwarray.normalize(arr, out=out) >>> print('ti.rankings = {}'.format(ub.urepr( >>> ti.rankings, nl=2, align=':', precision=5)))
- kwarray.one_hot_embedding(labels, num_classes, dim=1)[source]¶
Embedding labels to one-hot form.
- Parameters:
labels – (LongTensor) class labels, sized [N,].
num_classes – (int) number of classes.
dim (int) – dimension which will be created, if negative
- Returns:
encoded labels, sized [N,#classes].
- Return type:
Tensor
References
https://discuss.pytorch.org/t/convert-int-into-one-hot-format/507/4
Example
>>> # each element in target has to have 0 <= value < C >>> # xdoctest: +REQUIRES(module:torch) >>> import torch >>> labels = torch.LongTensor([0, 0, 1, 4, 2, 3]) >>> num_classes = max(labels) + 1 >>> t = one_hot_embedding(labels, num_classes) >>> assert all(row[y] == 1 for row, y in zip(t.numpy(), labels.numpy())) >>> import ubelt as ub >>> print(ub.urepr(t.numpy().tolist())) [ [1.0, 0.0, 0.0, 0.0, 0.0], [1.0, 0.0, 0.0, 0.0, 0.0], [0.0, 1.0, 0.0, 0.0, 0.0], [0.0, 0.0, 0.0, 0.0, 1.0], [0.0, 0.0, 1.0, 0.0, 0.0], [0.0, 0.0, 0.0, 1.0, 0.0], ] >>> t2 = one_hot_embedding(labels.numpy(), num_classes) >>> assert np.all(t2 == t.numpy()) >>> from kwarray.util_torch import _torch_available_devices >>> devices = _torch_available_devices() >>> if devices: >>> device = devices[0] >>> try: >>> t3 = one_hot_embedding(labels.to(device), num_classes) >>> except RuntimeError: >>> pass >>> assert np.all(t3.cpu().numpy() == t.numpy())
Example
>>> # xdoctest: +REQUIRES(module:torch) >>> import torch >>> nC = num_classes = 3 >>> labels = (torch.rand(10, 11, 12) * nC).long() >>> assert one_hot_embedding(labels, nC, dim=0).shape == (3, 10, 11, 12) >>> assert one_hot_embedding(labels, nC, dim=1).shape == (10, 3, 11, 12) >>> assert one_hot_embedding(labels, nC, dim=2).shape == (10, 11, 3, 12) >>> assert one_hot_embedding(labels, nC, dim=3).shape == (10, 11, 12, 3) >>> labels = (torch.rand(10, 11) * nC).long() >>> assert one_hot_embedding(labels, nC, dim=0).shape == (3, 10, 11) >>> assert one_hot_embedding(labels, nC, dim=1).shape == (10, 3, 11) >>> labels = (torch.rand(10) * nC).long() >>> assert one_hot_embedding(labels, nC, dim=0).shape == (3, 10) >>> assert one_hot_embedding(labels, nC, dim=1).shape == (10, 3)
- kwarray.one_hot_lookup(data, indices)[source]¶
Return value of a particular column for each row in data.
Each item in labels corresonds to a row in
data. Returns the index specified at each row.- Parameters:
data (ArrayLike) – N x C float array of values
indices (ArrayLike) – N integer array between 0 and C. This is an column index for each row in
data.
- Returns:
the selected probability for each row
- Return type:
ArrayLike
Note
This is functionally equivalent to
[row[c] for row, c in zip(data, indices)]except that it is works with pure matrix operations.Todo
- [ ] Allow the user to specify which dimension indices should be
zipped over. By default it should be dim=0
- [ ] Allow the user to specify which dimension indices should select
from. By default it should be dim=1.
Example
>>> from kwarray.util_torch import * # NOQA >>> data = np.array([ >>> [0, 1, 2], >>> [3, 4, 5], >>> [6, 7, 8], >>> [9, 10, 11], >>> ]) >>> indices = np.array([0, 1, 2, 1]) >>> res = one_hot_lookup(data, indices) >>> print('res = {!r}'.format(res)) res = array([ 0, 4, 8, 10]) >>> alt = np.array([row[c] for row, c in zip(data, indices)]) >>> assert np.all(alt == res)
Example
>>> # xdoctest: +REQUIRES(module:torch) >>> import torch >>> data = torch.from_numpy(np.array([ >>> [0, 1, 2], >>> [3, 4, 5], >>> [6, 7, 8], >>> [9, 10, 11], >>> ])) >>> indices = torch.from_numpy(np.array([0, 1, 2, 1])).long() >>> res = one_hot_lookup(data, indices) >>> print('res = {!r}'.format(res)) res = tensor([ 0, 4, 8, 10]...) >>> alt = torch.LongTensor([row[c] for row, c in zip(data, indices)]) >>> assert torch.all(alt == res)
- kwarray.padded_slice(data, slices, pad=None, padkw=None, return_info=False)[source]¶
Allows slices with out-of-bound coordinates. Any out of bounds coordinate will be sampled via padding.
- Parameters:
data (Sliceable) – data to slice into. Any channels must be the last dimension.
slices (slice | Tuple[slice, …]) – slice for each dimensions
ndim (int) – number of spatial dimensions
pad (List[int|Tuple]) – additional padding of the slice
padkw (Dict) – if unspecified defaults to
{'mode': 'constant'}return_info (bool, default=False) – if True, return extra information about the transform.
Note
Negative slices have a different meaning here then they usually do. Normally, they indicate a wrap-around or a reversed stride, but here they index into out-of-bounds space (which depends on the pad mode). For example a slice of -2:1 literally samples two pixels to the left of the data and one pixel from the data, so you get two padded values and one data value.
- SeeAlso:
embed_slice - finds the embedded slice and padding
- Returns:
- data_sliced: subregion of the input data (possibly with padding,
depending on if the original slice went out of bounds)
- Tuple[Sliceable, Dict] :
data_sliced : as above
transform : information on how to return to the original coordinates
- Currently a dict containing:
- st_dims: a list indicating the low and high space-time
coordinate values of the returned data slice.
The structure of this dictionary mach change in the future
- Return type:
Sliceable
Example
>>> import kwarray >>> data = np.arange(5) >>> slices = [slice(-2, 7)]
>>> data_sliced = kwarray.padded_slice(data, slices) >>> print(ub.urepr(data_sliced, with_dtype=False)) np.array([0, 0, 0, 1, 2, 3, 4, 0, 0])
>>> data_sliced = kwarray.padded_slice(data, slices, pad=[(3, 3)]) >>> print(ub.urepr(data_sliced, with_dtype=False)) np.array([0, 0, 0, 0, 0, 0, 1, 2, 3, 4, 0, 0, 0, 0, 0])
>>> data_sliced = kwarray.padded_slice(data, slice(3, 4), pad=[(1, 0)]) >>> print(ub.urepr(data_sliced, with_dtype=False)) np.array([2, 3])
- kwarray.random_combinations(items, size, num=None, rng=None)[source]¶
Yields
numcombinations of lengthsizefrom items in random order- Parameters:
items (List) – pool of items to choose from
size (int) – Number of items in each combination
num (int | None) – Number of combinations to generate. If None, generate them all.
rng (int | float | None | numpy.random.RandomState | random.Random) – seed or random number generator. Defaults to the global state of the python random module.
- Yields:
Tuple – a random combination of
itemsof lengthsize.
Example
>>> # xdoctest: +REQUIRES(module:scipy) >>> import ubelt as ub >>> items = list(range(10)) >>> size = 3 >>> num = 5 >>> rng = 0 >>> # xdoctest: +IGNORE_WANT >>> combos = list(random_combinations(items, size, num, rng)) >>> print('combos = {}'.format(ub.urepr(combos, nl=1))) combos = [ (0, 6, 9), (4, 7, 8), (4, 6, 7), (2, 3, 5), (1, 2, 4), ]
Example
>>> # xdoctest: +REQUIRES(module:scipy) >>> import ubelt as ub >>> items = list(zip(range(10), range(10))) >>> # xdoctest: +IGNORE_WANT >>> combos = list(random_combinations(items, 3, num=5, rng=0)) >>> print('combos = {}'.format(ub.urepr(combos, nl=1))) combos = [ ((0, 0), (6, 6), (9, 9)), ((4, 4), (7, 7), (8, 8)), ((4, 4), (6, 6), (7, 7)), ((2, 2), (3, 3), (5, 5)), ((1, 1), (2, 2), (4, 4)), ]
- kwarray.random_product(items, num=None, rng=None)[source]¶
Yields
numitems from the cartesian product of items in a random order.- Parameters:
items (List[Sequence]) – items to get caresian product of packed in a list or tuple. (note this deviates from api of
itertools.product())num (int | None) – maximum number of items to generate. If None generat them all
rng (int | float | None | numpy.random.RandomState | random.Random) – Seed or random number generator. Defaults to the global state of the python random module.
- Yields:
Tuple – a random item in the cartesian product
Example
>>> import ubelt as ub >>> items = [(1, 2, 3), (4, 5, 6, 7)] >>> rng = 0 >>> # xdoctest: +IGNORE_WANT >>> products = list(random_product(items, rng=0)) >>> print(ub.urepr(products, nl=0)) [(3, 4), (1, 7), (3, 6), (2, 7),... (1, 6), (2, 5), (2, 4)] >>> products = list(random_product(items, num=3, rng=0)) >>> print(ub.urepr(products, nl=0)) [(3, 4), (1, 7), (3, 6)]
Example
>>> # xdoctest: +REQUIRES(--profile) >>> rng = ensure_rng(0) >>> items = [np.array([15, 14]), np.array([27, 26]), >>> np.array([21, 22]), np.array([32, 31])] >>> num = 2 >>> for _ in range(100): >>> list(random_product(items, num=num, rng=rng))
- kwarray.robust_normalize(imdata, return_info=False, nodata=None, axis=None, dtype=<class 'numpy.float32'>, params='auto', mask=None)[source]¶
Normalize data intensities using heuristics to help put sensor data with extremely high or low contrast into a visible range.
This function is designed with an emphasis on getting something that is reasonable for visualization.
Todo
[x] Move to kwarray and renamed to robust_normalize?
[ ] Support for M-estimators?
- Parameters:
imdata (ndarray) – raw intensity data
return_info (bool) – if True, return information about the chosen normalization heuristic.
params (str | dict) – Can contain keys, low, high, or mid, scaling, extrema e.g. {‘low’: 0.1, ‘mid’: 0.8, ‘high’: 0.9, ‘scaling’: ‘sigmoid’} See documentation in
find_robust_normalizers().axis (None | int) – The axis to normalize over, if unspecified, normalize jointly
nodata (None | int) – A value representing nodata to leave unchanged during normalization, for example 0
dtype (type) – can be float32 or float64
mask (ndarray | None) – A mask indicating what pixels are valid and what pixels should be considered nodata. Mutually exclusive with
nodataargument. A mask value of 1 indicates a VALID pixel. A mask value of 0 indicates an INVALID pixel. Note this is the opposite of a masked array.
- Returns:
a floating point array with values between 0 and 1. if return_info is specified, also returns extra data
- Return type:
ndarray | Tuple[ndarray, Any]
Note
This is effectively a combination of
find_robust_normalizers()andnormalize().Example
>>> # xdoctest: +REQUIRES(module:scipy) >>> from kwarray.util_robust import * # NOQA >>> from kwarray.distributions import Mixture >>> import ubelt as ub >>> # A random mixture distribution for testing >>> data = Mixture.random(6).sample(3000) >>> param_basis = { >>> 'scaling': ['linear', 'sigmoid'], >>> 'high': [0.6, 0.8, 0.9, 1.0], >>> } >>> param_grid = list(ub.named_product(param_basis)) >>> param_grid += ['auto'] >>> param_grid += ['tukey'] >>> rows = [] >>> rows.append({'key': 'orig', 'result': data}) >>> for params in param_grid: >>> key = ub.urepr(params, compact=1) >>> result, info = robust_normalize(data, return_info=True, params=params) >>> print('key = {}'.format(key)) >>> print('info = {}'.format(ub.urepr(info, nl=1))) >>> rows.append({'key': key, 'info': info, 'result': result}) >>> # xdoctest: +REQUIRES(--show) >>> import seaborn as sns >>> import kwplot >>> kwplot.autompl() >>> pnum_ = kwplot.PlotNums(nSubplots=len(rows)) >>> for row in rows: >>> ax = kwplot.figure(fnum=1, pnum=pnum_()).gca() >>> sns.histplot(data=row['result'], kde=True, bins=128, ax=ax, stat='density') >>> ax.set_title(row['key'])
Example
>>> # xdoctest: +REQUIRES(module:kwimage) >>> from kwarray.util_robust import * # NOQA >>> import ubelt as ub >>> import kwimage >>> import kwarray >>> s = 512 >>> bit_depth = 11 >>> dtype = np.uint16 >>> max_val = int(2 ** bit_depth) >>> min_val = int(0) >>> rng = kwarray.ensure_rng(0) >>> background = np.random.randint(min_val, max_val, size=(s, s), dtype=dtype) >>> poly1 = kwimage.Polygon.random(rng=rng).scale(s / 2) >>> poly2 = kwimage.Polygon.random(rng=rng).scale(s / 2).translate(s / 2) >>> forground = np.zeros_like(background, dtype=np.uint8) >>> forground = poly1.fill(forground, value=255) >>> forground = poly2.fill(forground, value=122) >>> forground = (kwimage.ensure_float01(forground) * max_val).astype(dtype) >>> imdata = background + forground >>> normed, info = kwarray.robust_normalize(imdata, return_info=True) >>> print('info = {}'.format(ub.urepr(info, nl=1))) >>> # xdoctest: +REQUIRES(--show) >>> import kwplot >>> kwplot.autompl() >>> kwplot.imshow(imdata, pnum=(1, 2, 1), fnum=1) >>> kwplot.imshow(normed, pnum=(1, 2, 2), fnum=1)

- kwarray.seed_global(seed, offset=0)[source]¶
Seeds the python, numpy, and torch global random states
- Parameters:
seed (int) – seed to use
offset (int) – if specified, uses a different seed for each global random state separated by this offset. Defaults to 0.
- kwarray.setcover(candidate_sets_dict, items=None, set_weights=None, item_values=None, max_weight=None, algo='approx')[source]¶
Finds a feasible solution to the minimum weight maximum value set cover. The quality and runtime of the solution will depend on the backend algorithm selected.
- Parameters:
candidate_sets_dict (Dict[KT, List[VT]]) – a dictionary where keys are the candidate set ids and each value is a candidate cover set.
items (Optional[VT]) – the set of all items to be covered, if not specified, it is infered from the candidate cover sets
set_weights (Optional[Dict[KT, float]]) – maps candidate set ids to a cost for using this candidate cover in the solution. If not specified the weight of each candiate cover defaults to 1.
item_values (Optional[Dict[VT, float]]) – maps each item to a value we get for returning this item in the solution. If not specified the value of each item defaults to 1.
max_weight (Optional[float]) – if specified, the total cost of the returned cover is constrained to be less than this number.
algo (str) – specifies which algorithm to use. Can either be ‘approx’ for the greedy solution or ‘exact’ for the globally optimal solution. Note the ‘exact’ algorithm solves an integer-linear-program, which can be very slow and requires the pulp package to be installed.
- Returns:
a subdict of candidate_sets_dict containing the chosen solution.
- Return type:
Dict
Example
>>> candidate_sets_dict = { >>> 'a': [1, 2, 3, 8, 9, 0], >>> 'b': [1, 2, 3, 4, 5], >>> 'c': [4, 5, 7], >>> 'd': [5, 6, 7], >>> 'e': [6, 7, 8, 9, 0], >>> } >>> greedy_soln = setcover(candidate_sets_dict, algo='greedy') >>> print('greedy_soln = {}'.format(ub.urepr(greedy_soln, nl=0))) greedy_soln = {'a': [1, 2, 3, 8, 9, 0], 'c': [4, 5, 7], 'd': [5, 6, 7]} >>> # xdoc: +REQUIRES(module:pulp) >>> exact_soln = setcover(candidate_sets_dict, algo='exact') >>> print('exact_soln = {}'.format(ub.urepr(exact_soln, nl=0))) exact_soln = {'b': [1, 2, 3, 4, 5], 'e': [6, 7, 8, 9, 0]}
- kwarray.shuffle(items, rng=None)[source]¶
Shuffles a list inplace and then returns it for convinience
- Parameters:
items (list | ndarray) – data to shuffle
rng (int | float | None | numpy.random.RandomState | random.Random) – seed or random number gen
- Returns:
this is the input, but returned for convinience
- Return type:
Example
>>> list1 = [1, 2, 3, 4, 5, 6] >>> list2 = shuffle(list(list1), rng=1) >>> assert list1 != list2 >>> result = str(list2) >>> print(result) [3, 2, 5, 1, 4, 6]
- kwarray.standard_normal(size, mean=0, std=1, dtype=<class 'float'>, rng=<module 'numpy.random' from '/home/docs/checkouts/readthedocs.org/user_builds/kwarray/envs/main/lib/python3.11/site-packages/numpy/random/__init__.py'>)[source]¶
Draw samples from a standard Normal distribution with a specified mean and standard deviation.
- Parameters:
size (int | Tuple[int, …]) – shape of the returned ndarray
mean (float) – mean of the normal distribution. defaults to 0
std (float) – standard deviation of the normal distribution. defaults to 1.
dtype (type) – either np.float32 (default) or np.float64
rng (numpy.random.RandomState) – underlying random state
- Returns:
normally distributed random numbers with chosen size and dtype Extended typing
NDArray[Literal[size], Literal[dtype]]- Return type:
ndarray
Benchmark
>>> from timerit import Timerit >>> import kwarray >>> size = (300, 300, 3) >>> for timer in Timerit(100, bestof=10, label='dtype=np.float32'): >>> rng = kwarray.ensure_rng(0) >>> with timer: >>> ours = standard_normal(size, rng=rng, dtype=np.float32) >>> # Timed best=4.705 ms, mean=4.75 ± 0.085 ms for dtype=np.float32 >>> for timer in Timerit(100, bestof=10, label='dtype=np.float64'): >>> rng = kwarray.ensure_rng(0) >>> with timer: >>> theirs = standard_normal(size, rng=rng, dtype=np.float64) >>> # Timed best=9.327 ms, mean=9.794 ± 0.4 ms for rng.np.float64
- kwarray.standard_normal32(size, mean=0, std=1, rng=<module 'numpy.random' from '/home/docs/checkouts/readthedocs.org/user_builds/kwarray/envs/main/lib/python3.11/site-packages/numpy/random/__init__.py'>)[source]¶
Fast normally distributed random variables.
Uses the Box–Muller transform [WikiBoxMuller].
The difference between this function and
numpy.random.standard_normal()is that we use float32 arrays in the backend instead of float64. Halving the amount of bits that need to be manipulated can significantly reduce the execution time, and 32-bit precision is often good enough.- Parameters:
size (int | Tuple[int, …]) – shape of the returned ndarray
mean (float, default=0) – mean of the normal distribution
std (float, default=1) – standard deviation of the normal distribution
rng (numpy.random.RandomState) – underlying random state
- Returns:
normally distributed random numbers with chosen size.
- Return type:
ndarray[Any, Float32]
References
- SeeAlso:
Example
>>> # xdoctest: +REQUIRES(module:scipy) >>> import scipy >>> import scipy.stats >>> pts = 1000 >>> # Our numbers are normally distributed with high probability >>> rng = np.random.RandomState(28041990) >>> ours_a = standard_normal32(pts, rng=rng) >>> ours_b = standard_normal32(pts, rng=rng) + 2 >>> ours = np.concatenate((ours_a, ours_b)) # numerical stability? >>> p = scipy.stats.normaltest(ours)[1] >>> print('Probability our data is non-normal is: {:.4g}'.format(p)) Probability our data is non-normal is: 1.573e-14 >>> rng = np.random.RandomState(28041990) >>> theirs_a = rng.standard_normal(pts) >>> theirs_b = rng.standard_normal(pts) + 2 >>> theirs = np.concatenate((theirs_a, theirs_b)) >>> p = scipy.stats.normaltest(theirs)[1] >>> print('Probability their data is non-normal is: {:.4g}'.format(p)) Probability their data is non-normal is: 3.272e-11
Example
>>> pts = 1000 >>> rng = np.random.RandomState(28041990) >>> ours = standard_normal32(pts, mean=10, std=3, rng=rng) >>> assert np.abs(ours.std() - 3.0) < 0.1 >>> assert np.abs(ours.mean() - 10.0) < 0.1
Example
>>> # Test an even and odd numbers of points >>> assert standard_normal32(3).shape == (3,) >>> assert standard_normal32(2).shape == (2,) >>> assert standard_normal32(1).shape == (1,) >>> assert standard_normal32(0).shape == (0,) >>> assert standard_normal32((3, 1)).shape == (3, 1) >>> assert standard_normal32((3, 0)).shape == (3, 0)
- kwarray.standard_normal64(size, mean=0, std=1, rng=<module 'numpy.random' from '/home/docs/checkouts/readthedocs.org/user_builds/kwarray/envs/main/lib/python3.11/site-packages/numpy/random/__init__.py'>)[source]¶
Simple wrapper around rng.standard_normal to make an API compatible with
standard_normal32().- Parameters:
size (int | Tuple[int, …]) – shape of the returned ndarray
mean (float) – mean of the normal distribution. defaults to 0
std (float) – standard deviation of the normal distribution. defaults to 1.
rng (numpy.random.RandomState) – underlying random state
- Returns:
normally distributed random numbers with chosen size.
- Return type:
ndarray[Any, Float64]
- SeeAlso:
standard_normal
standard_normal32
Example
>>> pts = 1000 >>> rng = np.random.RandomState(28041994) >>> out = standard_normal64(pts, mean=10, std=3, rng=rng) >>> assert np.abs(out.std() - 3.0) < 0.1 >>> assert np.abs(out.mean() - 10.0) < 0.1
- kwarray.stats_dict(inputs, axis=None, nan=False, sum=False, extreme=True, n_extreme=False, median=False, shape=True, size=False, quantile='auto')[source]¶
Describe statistics about an input array
- Parameters:
inputs (ArrayLike) – set of values to get statistics of
axis (int) – if
inputsis ndarray then this specifies the axisnan (bool) – report number of nan items (TODO: rename to skipna)
sum (bool) – report sum of values
extreme (bool) – report min and max values
n_extreme (bool) – report extreme value frequencies
median (bool) – report median
size (bool) – report array size
shape (bool) – report array shape
quantile (str | bool | List[float]) – defaults to ‘auto’. Can also be a list of quantiles to compute. if truthy computes quantiles.
- Returns:
dictionary of common numpy statistics (min, max, mean, std, nMin, nMax, shape)
- Return type:
- SeeAlso:
scipy.stats.describe()pandas.DataFrame.describe()
Example
>>> # xdoctest: +IGNORE_WHITESPACE >>> from kwarray.util_averages import * # NOQA >>> axis = 0 >>> rng = np.random.RandomState(0) >>> inputs = rng.rand(10, 2).astype(np.float32) >>> stats = stats_dict(inputs, axis=axis, nan=False, median=True) >>> import ubelt as ub # NOQA >>> result = str(ub.urepr(stats, nl=1, precision=4, with_dtype=True)) >>> print(result) { 'mean': np.array([[0.5206, 0.6425]], dtype=np.float32), 'std': np.array([[0.2854, 0.2517]], dtype=np.float32), 'min': np.array([[0.0202, 0.0871]], dtype=np.float32), 'max': np.array([[0.9637, 0.9256]], dtype=np.float32), 'q_0.25': np.array([0.4271, 0.5329], dtype=np.float64), 'q_0.50': np.array([0.5584, 0.6805], dtype=np.float64), 'q_0.75': np.array([0.7343, 0.8607], dtype=np.float64), 'med': np.array([0.5584, 0.6805], dtype=np.float32), 'shape': (10, 2), }
Example
>>> # xdoctest: +IGNORE_WHITESPACE >>> from kwarray.util_averages import * # NOQA >>> axis = 0 >>> rng = np.random.RandomState(0) >>> inputs = rng.randint(0, 42, size=100).astype(np.float32) >>> inputs[4] = np.nan >>> stats = stats_dict(inputs, axis=axis, nan=True, quantile='auto') >>> import ubelt as ub # NOQA >>> result = str(ub.urepr(stats, nl=0, precision=1, strkeys=True)) >>> print(result)
Example
>>> import kwarray >>> import ubelt as ub >>> rng = kwarray.ensure_rng(0) >>> orig_inputs = rng.rand(1, 1, 2, 3) >>> param_grid = ub.named_product({ >>> #'axis': (None, 0, (0, 1), -1), >>> 'axis': [None], >>> 'percent_nan': [0, 0.5, 1.0], >>> 'nan': [True, False], >>> 'sum': [1], >>> 'extreme': [True], >>> 'n_extreme': [True], >>> 'median': [1], >>> 'size': [1], >>> 'shape': [1], >>> 'quantile': ['auto'], >>> }) >>> for params in param_grid: >>> kwargs = params.copy() >>> percent_nan = kwargs.pop('percent_nan', 0) >>> if percent_nan: >>> inputs = orig_inputs.copy() >>> inputs[rng.rand(*inputs.shape) < percent_nan] = np.nan >>> else: >>> inputs = orig_inputs >>> stats = kwarray.stats_dict(inputs, **kwargs) >>> print('---') >>> print('params = {}'.format(ub.urepr(params, nl=1))) >>> print('stats = {}'.format(ub.urepr(stats, nl=1)))
- kwarray.uniform(low=0.0, high=1.0, size=None, dtype=<class 'numpy.float32'>, rng=<module 'numpy.random' from '/home/docs/checkouts/readthedocs.org/user_builds/kwarray/envs/main/lib/python3.11/site-packages/numpy/random/__init__.py'>)[source]¶
Draws float32 samples from a uniform distribution.
Samples are uniformly distributed over the half-open interval
[low, high)(includes low, but excludes high).- Parameters:
low (float) – Lower boundary of the output interval. All values generated will be greater than or equal to low. Defaults to 0.
high (float) – Upper boundary of the output interval. All values generated will be less than high. Default to 1.
size (int | Tuple[int, …] | None) – Output shape. If the given shape is, e.g.,
(m, n, k), thenm * n * ksamples are drawn. If size isNone(default), a single value is returned iflowandhighare both scalars. Otherwise,np.broadcast(low, high).sizesamples are drawn.dtype (type) – either np.float32 or np.float64. Defaults to float32
rng (numpy.random.RandomState) – underlying random state
- Returns:
uniformly distributed random numbers with chosen size and dtype Extended typing
NDArray[Literal[size], Literal[dtype]]- Return type:
ndarray
Benchmark
>>> from timerit import Timerit >>> import kwarray >>> size = (300, 300, 3) >>> for timer in Timerit(100, bestof=10, label='dtype=np.float32'): >>> rng = kwarray.ensure_rng(0) >>> with timer: >>> ours = standard_normal(size, rng=rng, dtype=np.float32) >>> # Timed best=4.705 ms, mean=4.75 ± 0.085 ms for dtype=np.float32 >>> for timer in Timerit(100, bestof=10, label='dtype=np.float64'): >>> rng = kwarray.ensure_rng(0) >>> with timer: >>> theirs = standard_normal(size, rng=rng, dtype=np.float64) >>> # Timed best=9.327 ms, mean=9.794 ± 0.4 ms for rng.np.float64
- kwarray.uniform32(low=0.0, high=1.0, size=None, rng=<module 'numpy.random' from '/home/docs/checkouts/readthedocs.org/user_builds/kwarray/envs/main/lib/python3.11/site-packages/numpy/random/__init__.py'>)[source]¶
Draws float32 samples from a uniform distribution.
Samples are uniformly distributed over the half-open interval
[low, high)(includes low, but excludes high).- Parameters:
low (float, default=0.0) – Lower boundary of the output interval. All values generated will be greater than or equal to low.
high (float, default=1.0) – Upper boundary of the output interval. All values generated will be less than high.
size (int | Tuple[int, …] | None) – Output shape. If the given shape is, e.g.,
(m, n, k), thenm * n * ksamples are drawn. If size isNone(default), a single value is returned iflowandhighare both scalars. Otherwise,np.broadcast(low, high).sizesamples are drawn.
- Returns:
uniformly distributed random numbers with chosen size.
- Return type:
ndarray[Any, Float32]
Example
>>> rng = np.random.RandomState(0) >>> uniform32(low=0.0, high=1.0, size=None, rng=rng) 0.5488... >>> uniform32(low=0.0, high=1.0, size=2000, rng=rng).sum() 1004.94... >>> uniform32(low=-10, high=10.0, size=2000, rng=rng).sum() 202.44...
Benchmark
>>> from timerit import Timerit >>> import kwarray >>> size = 512 * 512 >>> for timer in Timerit(100, bestof=10, label='theirs: dtype=np.float64'): >>> rng = kwarray.ensure_rng(0) >>> with timer: >>> theirs = rng.uniform(size=size) >>> for timer in Timerit(100, bestof=10, label='theirs: dtype=np.float32'): >>> rng = kwarray.ensure_rng(0) >>> with timer: >>> theirs = rng.rand(size).astype(np.float32) >>> for timer in Timerit(100, bestof=10, label='ours: dtype=np.float32'): >>> rng = kwarray.ensure_rng(0) >>> with timer: >>> ours = uniform32(size=size)
- kwarray.unique_rows(arr, ordered=False, return_index=False)[source]¶
Like unique, but works on rows
- Parameters:
arr (NDArray) – must be a contiguous C style array
ordered (bool) – if true, keeps relative ordering
References
https://stackoverflow.com/questions/16970982/find-unique-rows-in-numpy-array
Example
>>> import kwarray >>> from kwarray.util_numpy import * # NOQA >>> rng = kwarray.ensure_rng(0) >>> arr = rng.randint(0, 2, size=(22, 3)) >>> arr_unique = unique_rows(arr) >>> print('arr_unique = {!r}'.format(arr_unique)) >>> arr_unique, idxs = unique_rows(arr, return_index=True, ordered=True) >>> assert np.all(arr[idxs] == arr_unique) >>> print('arr_unique = {!r}'.format(arr_unique)) >>> print('idxs = {!r}'.format(idxs)) >>> arr_unique, idxs = unique_rows(arr, return_index=True, ordered=False) >>> assert np.all(arr[idxs] == arr_unique) >>> print('arr_unique = {!r}'.format(arr_unique)) >>> print('idxs = {!r}'.format(idxs))